机器学习与人工智能
人工智能、机器学习、深度学习的关系
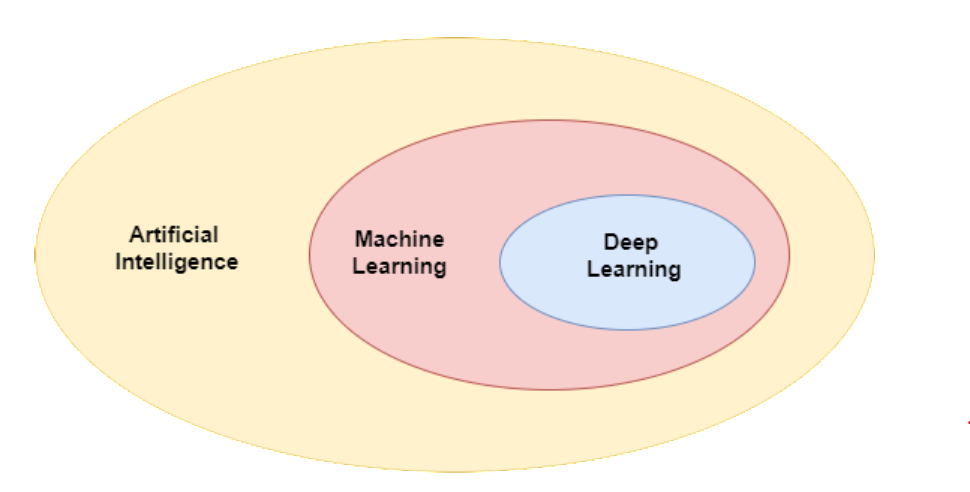
想象一下俄罗斯套娃,一个大娃娃里面套着中娃娃,中娃娃里面套着小娃娃。人工智能、机器学习和深度学习的关系就像这样:
- 人工智能(AI):最大的娃娃,最广泛的概念
- 机器学习(ML):中间的娃娃,AI 的一部分
- 深度学习(DL):最小的娃娃,机器学习的一部分
人工智能(AI)是什么?
人工智能是一个广泛的概念,指的是让机器展现出类似人类智能的技术。就像人类智能包括推理、学习、感知、理解语言等能力一样,AI 也试图让机器具备这些能力。
AI 的目标:
- 模拟人类的思维过程
- 解决需要人类智能才能完成的任务
- 在某些方面超越人类的能力
AI 的例子:
- 下棋程序(如 AlphaGo)
- 语音助手(如 Siri、小爱同学)
- 自动驾驶汽车
机器学习(ML)在 AI 中的位置
机器学习是实现人工智能的一种方法,但不是唯一方法。就像做菜可以有多种方法(炒、煮、蒸、烤),实现 AI 也有多种途径。
机器学习的特点:
- 不需要人工编写所有规则
- 从数据中自动学习规律
- 适合处理复杂、规则难以明确的问题
传统 AI vs 机器学习:
| 传统 AI 方法 | 机器学习方法 |
|---|---|
| 专家系统:人工编写规则 | 从数据中学习规则 |
| 逻辑推理:基于明确规则 | 模式识别:从数据找规律 |
| 适合规则明确的问题 | 适合复杂、模糊的问题 |
深度学习(DL)与机器学习
深度学习是机器学习的一个分支,使用多层神经网络来学习数据中的复杂模式。
深度学习的特点:
- 使用多层神经网络("深度"指层数多)
- 特别适合处理图像、声音、文本等非结构化数据
- 需要大量数据和计算资源
发展历史与演进
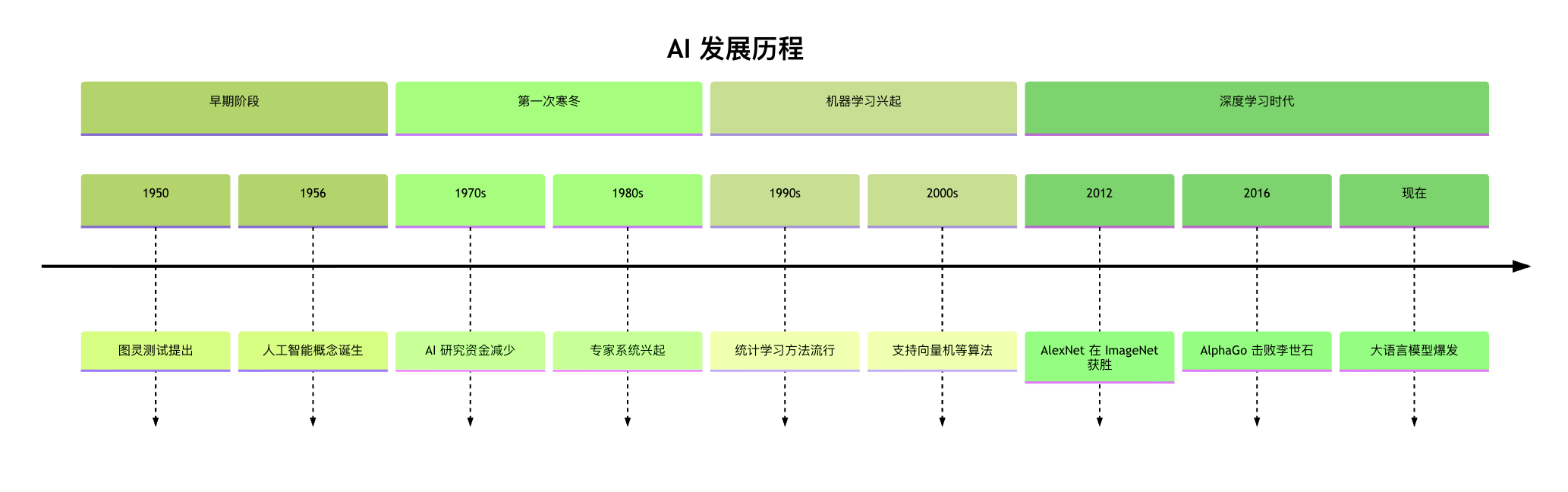
- 早期 AI(1950s-1970s):主要依靠人工编写的规则和逻辑推理
- 机器学习兴起(1980s-2000s):开始从数据中学习,但特征需要人工设计
- 深度学习时代(2010s-至今):自动学习特征,处理更复杂的问题
实例
让我们通过一个简单的例子来展示传统方法、机器学习和深度学习的区别,尝试识别手写数字。
方法一:传统方法(基于规则)
实例
# 传统方法:基于人工设计的规则识别手写数字
# 这只是一个概念性示例,实际中这种方法效果很差
def recognize_digit_by_rules(image):
"""
基于人工规则识别数字(简化示例)
"""
# 规则1:计算图像中的黑色像素数量
black_pixels = count_black_pixels(image)
# 规则2:计算图像的重心位置
center_x, center_y = calculate_center(image)
# 规则3:检测特定的形状特征
has_circle = detect_circle(image)
has_straight_line = detect_straight_line(image)
# 基于规则判断
if has_circle and black_pixels < 50:
return "0"
elif has_straight_line and center_y < image_height/2:
return "7"
# ... 更多规则
else:
return "无法识别"
# 问题:规则难以覆盖所有情况,且非常脆弱
# 这只是一个概念性示例,实际中这种方法效果很差
def recognize_digit_by_rules(image):
"""
基于人工规则识别数字(简化示例)
"""
# 规则1:计算图像中的黑色像素数量
black_pixels = count_black_pixels(image)
# 规则2:计算图像的重心位置
center_x, center_y = calculate_center(image)
# 规则3:检测特定的形状特征
has_circle = detect_circle(image)
has_straight_line = detect_straight_line(image)
# 基于规则判断
if has_circle and black_pixels < 50:
return "0"
elif has_straight_line and center_y < image_height/2:
return "7"
# ... 更多规则
else:
return "无法识别"
# 问题:规则难以覆盖所有情况,且非常脆弱
方法二:机器学习方法
实例
# 机器学习方法:使用传统特征提取 + 分类器
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 1. 人工设计特征(这是传统机器学习的局限)
def extract_features(image):
"""
人工设计特征
"""
features = []
# 特征1:黑色像素比例
features.append(count_black_pixels(image) / total_pixels)
# 特征2:图像重心
center_x, center_y = calculate_center(image)
features.extend([center_x, center_y])
# 特征3:边缘密度
features.append(calculate_edge_density(image))
# ... 更多手工设计的特征
return features
# 2. 提取所有训练数据的特征
X_train = [extract_features(img) for img in train_images]
y_train = train_labels
# 3. 训练模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 4. 测试
X_test = [extract_features(img) for img in test_images]
predictions = model.predict(X_test)
print(f"准确率:{accuracy_score(test_labels, predictions):.2f}")
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 1. 人工设计特征(这是传统机器学习的局限)
def extract_features(image):
"""
人工设计特征
"""
features = []
# 特征1:黑色像素比例
features.append(count_black_pixels(image) / total_pixels)
# 特征2:图像重心
center_x, center_y = calculate_center(image)
features.extend([center_x, center_y])
# 特征3:边缘密度
features.append(calculate_edge_density(image))
# ... 更多手工设计的特征
return features
# 2. 提取所有训练数据的特征
X_train = [extract_features(img) for img in train_images]
y_train = train_labels
# 3. 训练模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 4. 测试
X_test = [extract_features(img) for img in test_images]
predictions = model.predict(X_test)
print(f"准确率:{accuracy_score(test_labels, predictions):.2f}")
方法三:深度学习方法
实例
# 深度学习方法:端到端学习,自动提取特征
import tensorflow as tf
from tensorflow.keras import layers, models
# 1. 构建神经网络
model = models.Sequential([
# 自动学习低级特征(边缘、纹理等)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
# 自动学习中级特征(形状、组合等)
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 自动学习高级特征(整体模式)
layers.Conv2D(64, (3, 3), activation='relu'),
# 分类层
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax') # 10个数字类别
])
# 2. 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3. 直接使用原始图像数据训练(无需人工设计特征)
model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
# 4. 评估
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"深度学习模型准确率:{test_acc:.2f}")
import tensorflow as tf
from tensorflow.keras import layers, models
# 1. 构建神经网络
model = models.Sequential([
# 自动学习低级特征(边缘、纹理等)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
# 自动学习中级特征(形状、组合等)
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 自动学习高级特征(整体模式)
layers.Conv2D(64, (3, 3), activation='relu'),
# 分类层
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax') # 10个数字类别
])
# 2. 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3. 直接使用原始图像数据训练(无需人工设计特征)
model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
# 4. 评估
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"深度学习模型准确率:{test_acc:.2f}")
运行结果对比:
- 传统方法:准确率约 60-70%(且规则复杂)
- 机器学习:准确率约 85-92%(需要人工设计特征)
- 深度学习:准确率约 98-99%(自动学习特征)

点我分享笔记