Transformer 架构
Transformer 架构是一种基于自注意力机制(Self-Attention)的深度学习模型,由 Google 团队在 2017 年的论文《Attention Is All You Need》中首次提出。
Transformer 彻底改变了自然语言处理(NLP)领域,并成为现代大语言模型(如GPT、BERT等)的核心基础。
Transformer 与循环神经网络(RNN)类似,旨在处理自然语言等顺序输入数据,适用于机器翻译、文本摘要等任务。然而,与 RNN 不同,Transformer 无需逐步处理序列,而是可以一次性并行处理整个输入。
本章节将带你深入了解Transformer的核心思想、架构组成和工作原理,帮助你掌握这一革命性技术的基础知识。
Transformer 架构图
左边为编码器,右边为解码器。
![]()
1. 输入处理(底部)
- Embeddings/Projections(嵌入/投影层)
- 作用:将输入的单词(或 token)转换成数字向量(比如 "猫" → [0.2, -0.5, 0.7…])。
- 类比:就像给每个单词分配一个独特的"身份证号码",但更智能(包含语义信息)。
2. 编码器(左侧)
-
Multi-Headed Self-Attention(多头自注意力)
- 作用:让模型同时关注输入中的所有单词,并计算它们之间的关系。
- 举例:在句子"猫追老鼠"中,模型会学习"猫"和"老鼠"的关联比"猫"和"追"更强。
- 关键:并行处理所有单词,不像RNN需要逐个计算。
-
Norm(层归一化)
- 作用:稳定训练过程,防止数值过大或过小(类似"调音量"到合适范围)。
-
Feed-Forward Network(前馈神经网络)
- 作用:对每个单词的表示进行进一步加工(比如提取更复杂的特征)。
- 类比:像对"猫"的向量做一次深度解读,补充细节(比如"猫是哺乳动物")。
3. 解码器(右侧)
-
Masked Multi-Headed Self-Attention(掩码多头自注意力)
- 作用:训练时防止模型"作弊"(只能看到当前和之前的单词,不能看未来的)。
- 举例:生成"我爱__"时,模型只能基于"我""爱"预测下一个词,不能提前知道答案是"你"。
-
Multi-Headed Cross-Attention(多头交叉注意力)
- 作用:让解码器询问编码器:"关于输入,我应该重点关注什么?"
- 场景:翻译任务中,解码器生成英文时,会参考编码器处理的中文输入。
-
Norm 和 Feed-Forward Network
- 与编码器类似,对解码器的表示进行归一化和深度处理。
4. 输出(顶部)
- Linear(线性层)
- 作用:将解码器的输出映射到词表(比如预测下一个词是"你"的概率最高)。
- 举例:输入"我爱",模型输出"你"的概率可能是80%,"吃饭"的概率是10%…
Transformer 的核心思想
自注意力机制(Self-Attention)
Transformer 的核心思想是完全依赖注意力机制(无需循环或卷积结构)来捕捉输入序列中的全局依赖关系,从而实现高效的并行计算和更强的长距离依赖建模。
实例
def self_attention(query, key, value):
scores = torch.matmul(query, key.transpose(-2, -1)) # 计算相似度
weights = torch.softmax(scores, dim=-1) # 转换为概率分布
output = torch.matmul(weights, value) # 加权求和
return output
公式:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
- \(Q\)(Query)、\(K\)(Key)、\(V\)(Value)是通过输入线性变换得到的矩阵。
- \(\sqrt{d_k}\) 是缩放因子,防止点积过大导致梯度消失。
多头注意力(Multi-Head Attention)
- 将自注意力机制并行执行多次(多个"头"),每个头学习不同的注意力模式,最后拼接结果。
- 优势:捕捉更丰富的上下文信息(如局部/全局依赖、语法/语义特征)。
位置编码(Positional Encoding)
- Transformer 本身没有循环或卷积结构,无法直接感知序列顺序,因此需要显式地注入位置信息。
- 使用正弦/余弦函数或可学习的位置编码:
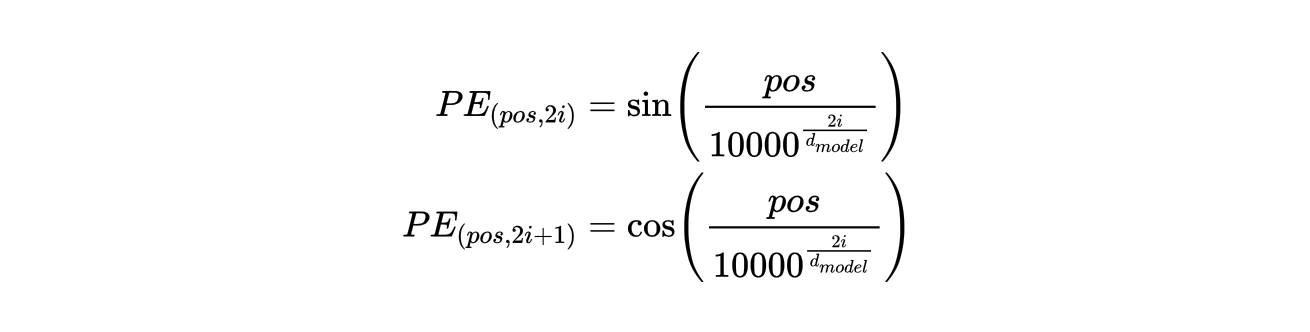
前馈神经网络(Feed-Forward Network, FFN)
- 每个位置的表示会通过一个两层全连接网络(含非线性激活,如ReLU)进行进一步变换。
- 公式:\( \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 \)。
残差连接与层归一化(Residual Connection & Layer Norm)
- 残差连接:将输入直接加到输出上(如 \( x + \text{Sublayer}(x) \)),缓解梯度消失。
- 层归一化:对每一层的输出进行归一化,加速训练。
并行处理能力
与传统RNN/LSTM不同,Transformer可以并行处理整个序列,极大提高了训练效率。
全局依赖建模
无论词与词之间的距离有多远,Transformer都能直接建立依赖关系,解决了长距离依赖问题。
编码器-解码器结构
Transformer采用经典的编码器-解码器架构,但每个部分都由多层相同的模块堆叠而成。
编码器(Encoder)
| 组件 | 功能描述 | 重要性 |
|---|---|---|
| 多头注意力 | 捕捉不同子空间的语义信息 | ★★★★★ |
| 前馈网络 | 非线性变换和特征提取 | ★★★★ |
| 残差连接 | 缓解梯度消失问题 | ★★★★ |
| 层归一化 | 稳定训练过程 | ★★★★ |
![]()
解码器(Decoder)
解码器在编码器基础上增加了:
- 掩码多头注意力:防止当前位置关注未来信息
- 编码器-解码器注意力:融合源语言信息
位置编码(Positional Encoding)
由于Transformer没有循环结构,需要显式地注入位置信息。
正弦位置编码公式
公式分为两部分,分别对应位置编码向量的偶数维和奇数维:偶数维(2i),奇数维(2i+1)。
参数说明:
pos:词在序列中的位置(如第 1 个词、第 2 个词等)。i:位置编码向量的维度索引(0 ≤ i < d_model/2)。d_model:位置编码的维度(通常与词向量的维度相同,如 512、768 等)。
位置编码的特点
- 相对位置敏感:可以学习到相对位置关系
- 长度可扩展:可以处理比训练时更长的序列
- 确定性:不需要学习,直接计算得到
实例
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
Transformer 的优势
与传统架构的对比
| 特性 | Transformer | RNN/LSTM | CNN |
|---|---|---|---|
| 并行性 | 完全并行 | 序列处理 | 局部并行 |
| 长距离依赖 | 直接建模 | 逐步传递 | 有限感受野 |
| 训练速度 | 快 | 慢 | 中等 |
| 内存消耗 | 较高 | 中等 | 低 |
实际应用优势
- 卓越的性能:在大多数NLP任务上达到state-of-the-art
- 可扩展性:模型规模可以轻松扩大(如GPT-3)
- 多模态适应:可应用于文本、图像、语音等多种数据
- 迁移学习友好:预训练+微调范式效果显著
实践练习
练习1:实现基础的自注意力
实例
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V, mask=None):
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = F.softmax(scores, dim=-1)
return torch.matmul(weights, V)
练习2:理解位置编码
- 可视化不同位置的位置编码向量
- 计算位置编码之间的相似度,观察位置关系
常见问题解答
Q: Transformer为什么比RNN更适合长文本? A: RNN需要逐步传递信息,长距离依赖容易丢失;而Transformer可以直接建立任意两个词之间的关系。
Q: 位置编码为什么选择正弦函数? A: 正弦函数具有周期性且可以表示相对位置关系,同时可以扩展到训练时未见过的序列长度。
Q: Transformer的主要计算瓶颈在哪里? A: 自注意力机制的空间复杂度是O(n²),处理长序列时会消耗大量内存。
总结
Transformer架构通过自注意力机制彻底改变了序列建模的方式,其核心优势在于:
- 强大的并行计算能力
- 高效的长期依赖建模
- 灵活的可扩展性
- 优异的性能表现
掌握Transformer的基本原理是学习现代NLP技术的重要基础,也是理解BERT、GPT等前沿模型的关键。

点我分享笔记