NLP 文本相似度计算
文本相似度计算是自然语言处理(NLP)中的一项基础任务,旨在量化两个文本片段之间的相似程度。这项技术在信息检索、问答系统、抄袭检测、推荐系统等多个领域都有广泛应用。
核心概念
- 语义相似度:衡量文本在含义上的接近程度
- 字面相似度:衡量文本在表面词汇上的重叠程度
- 向量空间模型:将文本表示为高维空间中的向量
- 距离度量:计算向量之间的距离或相似度
常用文本相似度计算方法
1. 基于词频的方法
词袋模型(Bag of Words)
实例
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'我喜欢自然语言处理',
'我爱学习NLP技术',
'文本相似度计算很有趣'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X.toarray())
corpus = [
'我喜欢自然语言处理',
'我爱学习NLP技术',
'文本相似度计算很有趣'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X.toarray())
TF-IDF 方法
实例
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(corpus)
print(tfidf_matrix.toarray())
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(corpus)
print(tfidf_matrix.toarray())
2. 基于词向量的方法
Word2Vec 相似度
实例
from gensim.models import Word2Vec
sentences = [
['我','喜欢','自然语言处理'],
['我','爱','学习','NLP','技术'],
['文本','相似度','计算','很','有趣']
]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
vector = model.wv['自然语言处理'] # 获取词向量
sentences = [
['我','喜欢','自然语言处理'],
['我','爱','学习','NLP','技术'],
['文本','相似度','计算','很','有趣']
]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
vector = model.wv['自然语言处理'] # 获取词向量
句子向量计算
实例
import numpy as np
def sentence_vector(sentence, model):
vectors = [model.wv[word] for word in sentence if word in model.wv]
return np.mean(vectors, axis=0) if vectors else np.zeros(model.vector_size)
sentence_vec1 = sentence_vector(['我','喜欢','自然语言处理'], model)
sentence_vec2 = sentence_vector(['我','爱','NLP'], model)
def sentence_vector(sentence, model):
vectors = [model.wv[word] for word in sentence if word in model.wv]
return np.mean(vectors, axis=0) if vectors else np.zeros(model.vector_size)
sentence_vec1 = sentence_vector(['我','喜欢','自然语言处理'], model)
sentence_vec2 = sentence_vector(['我','爱','NLP'], model)
3. 基于预训练模型的方法
BERT 相似度计算
实例
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("这是一个示例句子", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("这是一个示例句子", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
相似度度量指标
常用距离度量方法
| 方法名称 | 公式 | 特点 |
|---|---|---|
| 余弦相似度 | cos(θ) = (A·B)/(|A||B|) | 忽略向量长度,专注方向 |
| 欧氏距离 | √Σ(Ai-Bi)² | 考虑向量绝对位置 |
| 曼哈顿距离 | Σ|Ai-Bi| | 对异常值不敏感 |
| Jaccard相似度 | |A∩B|/|A∪B| | 适用于集合相似度 |
代码实现示例
实例
from sklearn.metrics.pairwise import cosine_similarity
# 计算余弦相似度
similarity = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])
print(f"文本相似度: {similarity[0][0]:.4f}")
# 计算余弦相似度
similarity = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])
print(f"文本相似度: {similarity[0][0]:.4f}")
实践应用示例
新闻标题相似度检测
实例
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 示例数据
titles = [
"苹果发布新款iPhone手机",
"苹果公司推出最新智能手机",
"微软公布季度财报",
"谷歌宣布新的人工智能计划"
]
# 计算相似度矩阵
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(titles)
similarities = cosine_similarity(tfidf_matrix)
# 显示结果
df = pd.DataFrame(similarities, columns=titles, index=titles)
print(df)
from sklearn.metrics.pairwise import cosine_similarity
# 示例数据
titles = [
"苹果发布新款iPhone手机",
"苹果公司推出最新智能手机",
"微软公布季度财报",
"谷歌宣布新的人工智能计划"
]
# 计算相似度矩阵
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(titles)
similarities = cosine_similarity(tfidf_matrix)
# 显示结果
df = pd.DataFrame(similarities, columns=titles, index=titles)
print(df)
结果分析
苹果发布新款iPhone手机 苹果公司推出最新智能手机 微软公布季度财报 谷歌宣布新的人工智能计划 苹果发布新款iPhone手机 1.000000 0.723417 0.000000 0.000000 苹果公司推出最新智能手机 0.723417 1.000000 0.000000 0.000000 微软公布季度财报 0.000000 0.000000 1.000000 0.204598 谷歌宣布新的人工智能计划 0.000000 0.000000 0.204598 1.000000
进阶技术与挑战
1. 处理语义相似但词汇不同的文本
实例
text1 = "我喜欢猫"
text2 = "我讨厌狗"
# 表面相似度低,但语义上都是表达对动物的态度
text2 = "我讨厌狗"
# 表面相似度低,但语义上都是表达对动物的态度
2. 解决一词多义问题
实例
# "苹果"可以指水果或公司
text1 = "苹果很甜"
text2 = "苹果市值创新高"
text1 = "苹果很甜"
text2 = "苹果市值创新高"
3. 长文本相似度计算
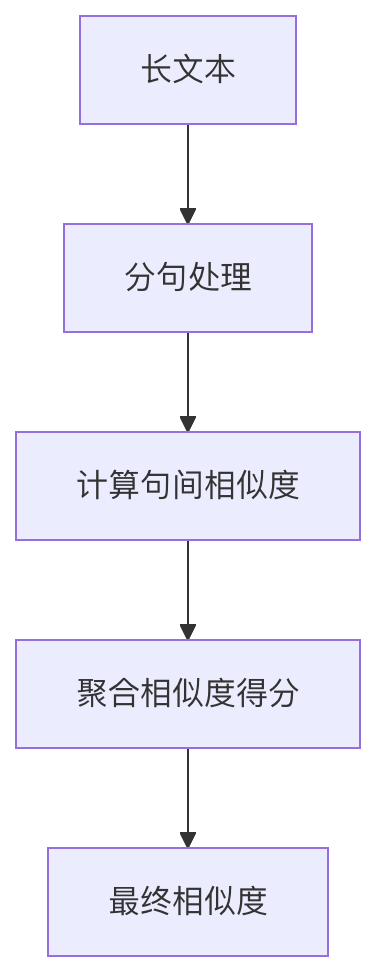
最佳实践建议
数据预处理很重要
- 统一大小写
- 去除停用词
- 词干提取/词形还原
根据场景选择方法
- 短文本:BERT等预训练模型
- 长文档:TF-IDF + 余弦相似度
- 实时系统:Word2Vec等轻量模型
考虑计算效率
- 大规模数据使用近似最近邻(ANN)算法
- 考虑使用Faiss等高效相似度搜索库
持续评估优化
- 建立人工评估集
- 监控生产环境效果
- 定期更新模型

点我分享笔记