BERT系列模型
BERT(Bidirectional Encoder Representations from Transformers)是2018年由Google提出的革命性自然语言处理模型,它彻底改变了NLP领域的研究和应用范式。
本文将系统介绍BERT的核心原理、训练方法、微调技巧以及主流变体模型。
BERT的架构与训练
下图展示了 BERT(Bidirectional Encoder Representations from Transformers) 模型的核心架构和预训练过程中的掩码语言建模(Masked Language Modeling, MLM)任务。
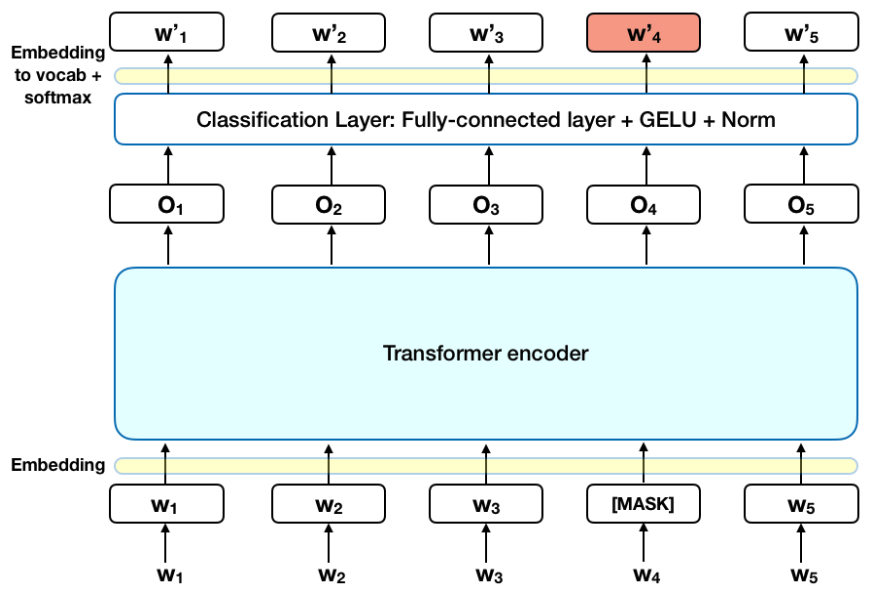
1. 输入层(Embedding)
- 输入序列:由词(或子词)组成的文本,例如
[W₁, W₂, W₃, [MASK], W₅, W₆, W₇, W₂, W₃, W₄, W₅]。[MASK]是 BERT 在预训练时随机遮蔽的词(如原文中的W₄被替换为[MASK])。
- Embedding 层:将每个词转换为固定维度的向量表示(如 768 维),包含:
- 词嵌入(Token Embeddings):词汇的语义信息。
- 位置嵌入(Position Embeddings):词在序列中的位置信息。
- 段嵌入(Segment Embeddings):区分句子(对句对任务有用,如图中未显式展示)。
2. Transformer 编码器(Transformer Encoder)
- 多层 Transformer 块:图中未展开细节,但每个块包含:
- 自注意力机制(Self-Attention):双向捕捉上下文依赖(BERT 的核心特性)。
- 前馈神经网络(Feed-Forward Network):非线性变换。
- 残差连接与层归一化:稳定训练过程。
- 输出:每个输入词对应的上下文相关向量表示(如
O₁, O₂, ..., O₅)。
3. 掩码语言建模(MLM)任务
- 目标:预测被遮蔽的词
[MASK]对应的原始词(图中W₄)。 - 分类层(Classification Layer):
- 全连接层(Fully-Connected Layer):将 Transformer 输出的向量(如
O₄)映射到词汇表大小的维度。 - 激活函数 GELU:高斯误差线性单元(BERT 采用的非线性函数)。
- 层归一化(Norm):标准化输出。
- Softmax:计算词汇表中每个词的概率,选择概率最高的词作为预测结果(如
W'₁, W'₂, ..., W'₅是候选词)。
- 全连接层(Fully-Connected Layer):将 Transformer 输出的向量(如
Transformer编码器结构
BERT基于Transformer的编码器部分构建,其核心是多层自注意力机制:
实例
# 简化的Transformer编码器层
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048):
super().__init__()
self.self_attn = MultiheadAttention(d_model, nhead)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, src):
# 自注意力机制
src2 = self.self_attn(src, src, src)[0]
src = src + self.norm1(src2)
# 前馈网络
src2 = self.linear2(F.relu(self.linear1(src)))
src = src + self.norm2(src2)
return src
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048):
super().__init__()
self.self_attn = MultiheadAttention(d_model, nhead)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, src):
# 自注意力机制
src2 = self.self_attn(src, src, src)[0]
src = src + self.norm1(src2)
# 前馈网络
src2 = self.linear2(F.relu(self.linear1(src)))
src = src + self.norm2(src2)
return src
关键创新:双向上下文建模
与传统语言模型不同,BERT通过以下两种预训练任务实现双向上下文理解:
- Masked Language Model (MLM):随机遮盖15%的输入token,预测被遮盖的词
- Next Sentence Prediction (NSP):判断两个句子是否连续出现
训练参数与配置
| 参数 | BERT-base | BERT-large |
|---|---|---|
| 层数 | 12 | 24 |
| 隐藏层大小 | 768 | 1024 |
| 注意力头数 | 12 | 16 |
| 总参数量 | 110M | 340M |
BERT的微调方法
标准微调流程
- 任务适配层添加:根据下游任务添加分类/回归层
- 学习率设置:通常使用较小的学习率(2e-5到5e-5)
- 批次大小:16或32是常见选择
- 训练周期:2-4个epoch通常足够
高效微调技术
实例
# 使用HuggingFace Transformers进行微调示例
from transformers import BertForSequenceClassification, Trainer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
from transformers import BertForSequenceClassification, Trainer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
常用微调策略对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| 全参数微调 | 性能最优 | 计算成本高 |
| 特征提取(冻结BERT) | 计算高效 | 性能次优 |
| 适配器(Adapter) | 参数高效 | 需要架构修改 |
| 提示学习(Prompt) | 小样本效果好 | 需要设计提示模板 |
主流BERT变体模型
RoBERTa (Robustly Optimized BERT)
- 改进点:
- 更大的批次(8k vs 256)
- 更长的训练时间
- 移除NSP任务
- 动态遮盖模式
- 性能:在GLUE基准上平均提升2-3%
ALBERT (A Lite BERT)
- 核心创新:
- 参数共享(跨层共享注意力参数)
- 嵌入分解(将词嵌入分解为两个小矩阵)
- 效果:参数量减少89%,速度提升1.7倍
其他重要变体
- DistilBERT:通过知识蒸馏压缩模型
- ELECTRA:用生成器-判别器架构替代MLM
- SpanBERT:优化对文本跨度的建模
中文BERT模型
中文预训练模型概览
| 模型 | 机构 | 特点 |
|---|---|---|
| BERT-wwm | 哈工大 | 全词遮盖(Whole Word Masking) |
| RoBERTa-wwm-ext | 哈工大 | 扩展训练数据 |
| ERNIE (百度) | 百度 | 融入知识图谱 |
| NEZHA | 华为 | 相对位置编码 |
中文BERT使用示例
实例
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("自然语言处理很有趣", return_tensors="pt")
outputs = model(**inputs)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("自然语言处理很有趣", return_tensors="pt")
outputs = model(**inputs)
中文任务微调建议
- 使用全词遮盖(wwm)版本效果更好
- 注意处理中文分词边界问题
- 对于专业领域,考虑领域自适应预训练
实践建议与资源
学习路线图
推荐资源
- 论文:
- 原始BERT论文(arXiv:1810.04805)
- RoBERTa、ALBERT等变体论文
- 代码库:
- HuggingFace Transformers
- 中文BERT的GitHub实现
- 在线课程:
- Coursera自然语言处理专项课程
- 李宏毅深度学习课程
通过系统学习和实践,BERT系列模型可以成为你解决NLP问题的强大工具。建议从基础版本开始,逐步探索更高级的变体和优化技术。

点我分享笔记