循环神经网络(RNN)
循环神经网络(Recurrent Neural Network,RNN) 是一种专门处理序列数据(如文本、语音、时间序列)的神经网络。
与传统的前馈神经网络不同,RNN 具有"记忆"能力,能够保存之前步骤的信息。
循环神经网络能够利用前一步的隐藏状态(Hidden State)来影响当前步骤的输出,从而捕捉序列中的时序依赖关系。
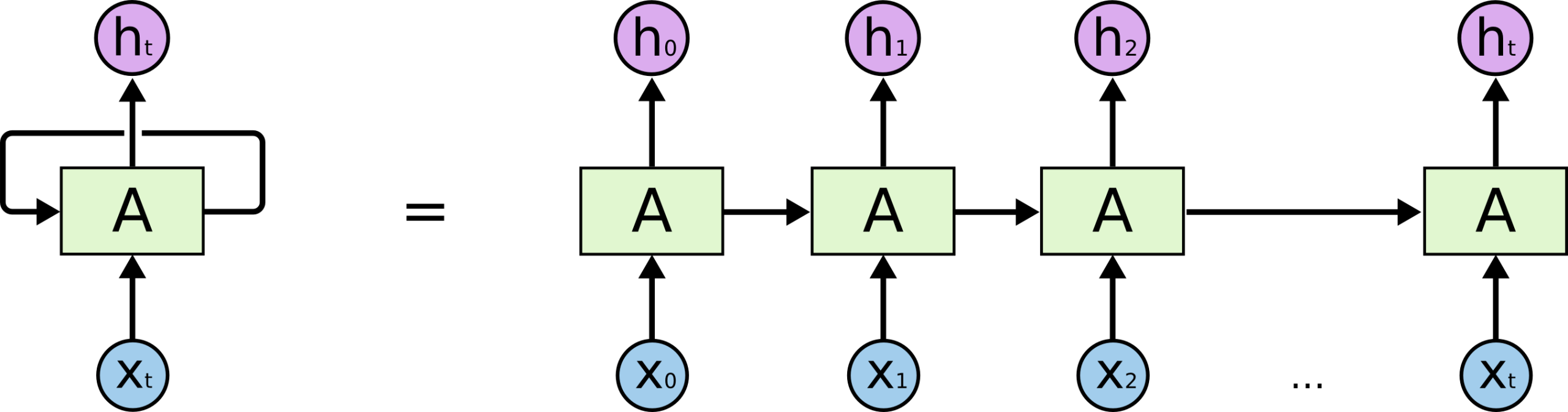
RNN 的核心思想
RNN 的核心在于循环连接(Recurrent Connection),即网络的输出不仅取决于当前输入,还取决于之前所有时间步的输入。这种结构使 RNN 能够处理任意长度的序列数据。
传统神经网络:输入和输出是独立的(例如图像分类,单张图片之间无关联)。
RNN:通过循环连接(Recurrent Connection)将上一步的隐藏状态传递到下一步,形成"记忆"。
每一步的输入 = 当前数据 + 上一步的隐藏状态。
输出不仅依赖当前输入,还依赖之前所有步骤的上下文。
就像人阅读句子时,理解当前单词会依赖前面读过的内容(例如"他打开了__",你会预测"门"或"书")。
实例
import numpy as np
class SimpleRNN:
def __init__(self, input_size, hidden_size):
self.Wx = np.random.randn(hidden_size, input_size) # 输入权重
self.Wh = np.random.randn(hidden_size, hidden_size) # 隐藏状态权重
self.b = np.zeros((hidden_size, 1)) # 偏置项
def forward(self, x, h_prev):
h_next = np.tanh(np.dot(self.Wx, x) + np.dot(self.Wh, h_prev) + self.b)
return h_next
RNN 的工作机制
RNN 在每个时间步 t 执行以下计算:
- 接收当前输入 xₜ 和前一时刻的隐藏状态 hₜ₋₁
- 计算新的隐藏状态 hₜ = f(Wₕₕ·hₜ₋₁ + Wₓₕ·xₜ + b)
- 产生输出 yₜ = g(Wₕᵧ·hₜ + c)
其中 f 和 g 通常是激活函数(如 tanh 或 softmax)。
RNN 的优缺点
优点:
- 能够处理变长序列
- 理论上可以记住任意长度的历史信息
- 参数共享(同一组权重用于所有时间步)
缺点:
- 梯度消失/爆炸问题(难以学习长期依赖)
- 计算效率较低(无法并行处理时间步)
长短期记忆网络(LSTM)
LSTM(Long Short-Term Memory)是 RNN 的一种改进架构,专门设计来解决标准 RNN 的长期依赖问题。
2.1 LSTM 的核心结构
LSTM 引入了三个门控机制和一个记忆单元:
| 组件 | 功能 |
|---|---|
| 输入门 | 控制新信息的流入 |
| 遗忘门 | 决定丢弃哪些旧信息 |
| 输出门 | 控制输出的信息量 |
| 记忆单元 | 保存长期状态 |
实例
class LSTMCell:
def __init__(self, input_size, hidden_size):
# 组合所有门的权重
self.W = np.random.randn(4*hidden_size, input_size+hidden_size)
self.b = np.random.randn(4*hidden_size, 1)
def forward(self, x, h_prev, c_prev):
combined = np.vstack((h_prev, x))
gates = np.dot(self.W, combined) + self.b
# 分割得到各个门
f_gate = sigmoid(gates[:hidden_size]) # 遗忘门
i_gate = sigmoid(gates[hidden_size:2*hidden_size]) # 输入门
o_gate = sigmoid(gates[2*hidden_size:3*hidden_size]) # 输出门
c_candidate = np.tanh(gates[3*hidden_size:]) # 候选记忆
# 更新记忆和隐藏状态
c_next = f_gate * c_prev + i_gate * c_candidate
h_next = o_gate * np.tanh(c_next)
return h_next, c_next
LSTM 如何解决长期依赖问题
- 选择性记忆:遗忘门可以决定保留或丢弃特定信息
- 梯度通路:记忆单元提供了相对直接的梯度传播路径
- 信息保护:记忆内容不会被每个时间步的操作直接修改
门控循环单元(GRU)
GRU(Gated Recurrent Unit)是 LSTM 的简化版本,在保持相似性能的同时减少了参数数量。
GRU 的核心结构
GRU 合并了 LSTM 的某些组件:
| 组件 | 功能 |
|---|---|
| 更新门 | 决定保留多少旧信息 |
| 重置门 | 决定如何组合新旧信息 |
| 候选激活 | 基于重置门计算的新状态 |
实例
class GRUCell:
def __init__(self, input_size, hidden_size):
self.W = np.random.randn(3*hidden_size, input_size+hidden_size)
self.b = np.random.randn(3*hidden_size, 1)
def forward(self, x, h_prev):
combined = np.vstack((h_prev, x))
gates = np.dot(self.W, combined) + self.b
# 分割门控信号
z = sigmoid(gates[:hidden_size]) # 更新门
r = sigmoid(gates[hidden_size:2*hidden_size]) # 重置门
h_candidate = np.tanh(np.dot(self.W[2*hidden_size:],
np.vstack((r*h_prev, x))) + self.b[2*hidden_size:]
# 更新隐藏状态
h_next = (1-z)*h_prev + z*h_candidate
return h_next
GRU vs LSTM
| 特性 | GRU | LSTM |
|---|---|---|
| 参数数量 | 较少 | 较多 |
| 训练速度 | 更快 | 较慢 |
| 记忆单元 | 无 | 有 |
| 门控数量 | 2个 | 3个 |
| 性能 | 小数据集更好 | 大数据集可能更好 |
双向 RNN(Bi-RNN)
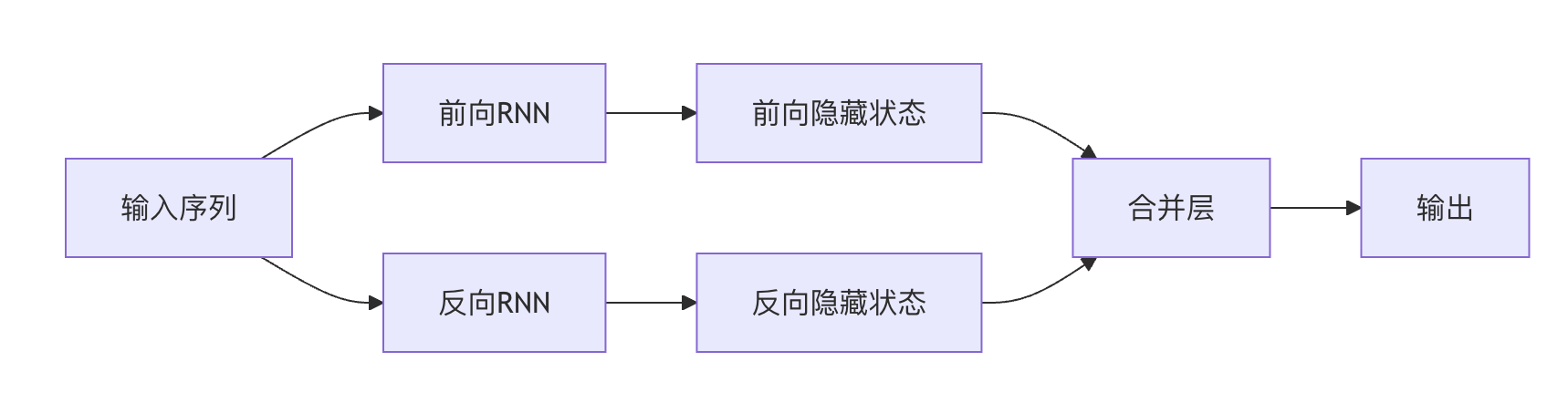
双向 RNN 通过同时考虑过去和未来的上下文信息,增强了序列建模能力。
双向 RNN 架构
Bi-RNN 包含两个独立的 RNN 层:
- 前向层:按时间顺序处理序列
- 反向层:按时间逆序处理序列
最终输出是这两个方向输出的组合(通常为拼接或求和)。
双向 RNN 的应用场景
- 自然语言处理:词性标注、命名实体识别
- 语音识别:利用前后语境提高准确率
- 生物信息学:蛋白质结构预测
- 时间序列预测:考虑历史与未来趋势
双向 LSTM/GRU
现代应用中,双向 RNN 通常使用 LSTM 或 GRU 作为基础单元:
实例
model.add(Bidirectional(LSTM(64))) # 创建双向LSTM层
实践练习
练习 1:实现简单 RNN
使用 Python 和 NumPy 实现一个能够处理字符级文本生成的简单 RNN。
练习 2:LSTM 情感分析
使用 Keras 构建一个基于 LSTM 的电影评论情感分类器。
练习 3:双向 GRU 命名实体识别
实现一个双向 GRU 模型,用于识别文本中的人名、地名等实体。
练习 4:比较实验
在同一数据集上比较 Vanilla RNN、LSTM 和 GRU 的性能差异。
总结与进阶学习
RNN 及其变体是处理序列数据的强大工具。要深入掌握:
- 理解梯度在 RNN 中的传播方式
- 学习注意力机制如何增强 RNN
- 探索 Transformer 架构与 RNN 的关系
- 实践各种序列建模任务(机器翻译、语音合成等)

点我分享笔记