序列到序列模型
序列到序列(Sequence-to-Sequence, Seq2Seq)模型是自然语言处理(NLP)中的一种重要架构,专门用于将一个序列转换为另一个序列的任务。这种模型的核心思想是接受一个长度可变的输入序列,生成一个长度可变的输出序列。
基本概念
Seq2Seq模型属于编码器-解码器(Encoder-Decoder)架构:
- 编码器:将输入序列编码为一个固定长度的上下文向量(context vector)
- 解码器:根据上下文向量逐步生成输出序列
典型特征
- 输入和输出序列长度可以不同
- 适用于多种语言间的转换任务
- 能够处理变长序列数据
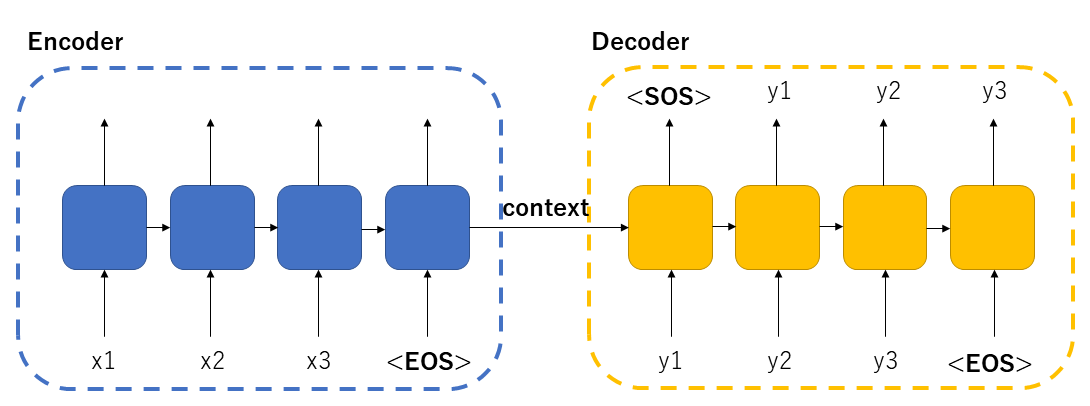
Seq2Seq模型的核心原理
基础架构组成
编码器(Encoder)
编码器通常使用RNN(如LSTM或GRU)处理输入序列,逐步将序列信息压缩到隐藏状态中,最终生成代表整个输入序列的上下文向量。
解码器(Decoder)
解码器从上下文向量开始,逐步生成输出序列的每个元素,直到产生结束标记。
工作流程
- 编码器读取输入序列,生成上下文向量
- 解码器初始化隐藏状态为上下文向量
- 解码器逐步生成输出序列元素
- 当生成结束标记时停止
关键技术改进
- 注意力机制(Attention):解决长序列信息丢失问题
- Transformer架构:完全基于自注意力机制的Seq2Seq模型
- Beam Search:改进解码策略,提高生成质量
实例
# 简化的Seq2Seq模型伪代码
class Seq2Seq(nn.Module):
def __init__(self):
self.encoder = RNN(input_size, hidden_size)
self.decoder = RNN(hidden_size, output_size)
def forward(self, input_seq):
# 编码阶段
hidden = self.encoder(input_seq)
# 解码阶段
outputs = self.decoder(hidden)
return outputs
class Seq2Seq(nn.Module):
def __init__(self):
self.encoder = RNN(input_size, hidden_size)
self.decoder = RNN(hidden_size, output_size)
def forward(self, input_seq):
# 编码阶段
hidden = self.encoder(input_seq)
# 解码阶段
outputs = self.decoder(hidden)
return outputs
Seq2Seq在机器翻译中的应用
机器翻译任务特点
- 输入和输出都是文本序列
- 两种语言间的序列长度通常不对应
- 需要理解源语言并生成目标语言
典型应用案例
- Google神经机器翻译(GNMT)系统
- Facebook的Fairseq翻译系统
- 开源工具OpenNMT
实现要点
- 使用双向RNN编码器捕获上下文信息
- 加入注意力机制处理长句子
- 采用子词切分(Subword Tokenization)处理罕见词
实例
# 机器翻译模型示例
translation_model = Seq2Seq(
encoder=BiLSTM(vocab_size=src_vocab_size),
decoder=LSTM(vocab_size=tgt_vocab_size),
attention=DotProductAttention()
)
translation_model = Seq2Seq(
encoder=BiLSTM(vocab_size=src_vocab_size),
decoder=LSTM(vocab_size=tgt_vocab_size),
attention=DotProductAttention()
)
Seq2Seq在文本摘要中的应用
文本摘要任务分类
| 摘要类型 | 特点 | Seq2Seq适用性 |
|---|---|---|
| 抽取式摘要 | 从原文选取重要句子 | 不适用 |
| 生成式摘要 | 生成新的概括性文本 | 非常适合 |
关键技术挑战
- 处理长文档的信息压缩
- 保持摘要的连贯性和准确性
- 避免重复生成相同内容
解决方案
- 指针生成网络:结合抽取和生成方法
- 覆盖机制:跟踪已生成内容,避免重复
- 强化学习:优化ROUGE等摘要指标
实例
# 文本摘要模型示例
summarizer = Seq2Seq(
encoder=TransformerEncoder(),
decoder=TransformerDecoder(),
pointer_network=True
)
summarizer = Seq2Seq(
encoder=TransformerEncoder(),
decoder=TransformerDecoder(),
pointer_network=True
)
Seq2Seq在对话生成中的应用
对话系统类型对比
| 类型 | 特点 | Seq2Seq适用性 |
|---|---|---|
| 任务型对话 | 完成特定任务 | 有限适用 |
| 闲聊型对话 | 开放领域交流 | 非常适合 |
对话生成的特殊性
- 需要保持对话的连贯性
- 响应应适合对话上下文
- 避免生成通用无意义的回复
改进方法
- 个性化嵌入:加入说话者特征
- 情感控制:生成特定情感色彩的回复
- 对抗训练:提高回复的自然度
实例
# 对话生成模型示例
chatbot = Seq2Seq(
encoder=GRU(hidden_size=512),
decoder=GRU(hidden_size=512),
personality_embedding=True
)
chatbot = Seq2Seq(
encoder=GRU(hidden_size=512),
decoder=GRU(hidden_size=512),
personality_embedding=True
)
Seq2Seq模型的训练与优化
训练流程
- 准备平行语料数据集
- 定义损失函数(通常为交叉熵)
- 使用教师强制(Teacher Forcing)训练
- 验证集调参
常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 梯度消失 | 长序列依赖 | 使用LSTM/GRU,或Transformer |
| 曝光偏差 | 训练测试不一致 | 计划采样(Scheduled Sampling) |
| 通用回复 | 最大似然偏差 | 对抗训练或强化学习 |
评估指标
- BLEU:机器翻译常用指标
- ROUGE:文本摘要常用指标
- 人工评估:对话系统重要补充
总结与展望
Seq2Seq模型作为NLP领域的核心技术,已经从最初的简单RNN架构发展到如今强大的Transformer模型。它在机器翻译、文本摘要、对话生成等任务中展现出强大能力。未来发展方向包括:
- 更高效的长序列处理
- 少样本/零样本学习能力
- 多模态序列转换
- 更可控的内容生成
通过理解Seq2Seq模型的原理和应用,你已经掌握了NLP中一项强大的工具,可以开始构建自己的序列转换应用了!

点我分享笔记