TensorFlow 模型评估与监控
一、模型评估基础概念
在机器学习项目中,模型评估是验证模型性能的关键步骤。它帮助我们了解模型在真实场景中的表现,并指导我们进行模型优化。
1.1 为什么需要模型评估
- 性能验证:确认模型是否达到预期效果
- 模型选择:比较不同模型的优劣
- 参数调优:指导超参数调整方向
- 避免过拟合:检测模型是否过度适应训练数据
1.2 评估指标类型
| 指标类型 | 适用场景 | 常见指标 |
|---|---|---|
| 分类指标 | 分类问题 | 准确率、精确率、召回率、F1分数 |
| 回归指标 | 回归问题 | MSE、MAE、R² |
| 聚类指标 | 无监督学习 | 轮廓系数、Davies-Bouldin指数 |
二、TensorFlow 评估工具
TensorFlow 提供了多种工具和方法来评估模型性能。
2.1 内置评估指标
实例
import tensorflow as tf
# 常用分类指标
metrics = [
tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
tf.keras.metrics.AUC()
]
# 常用回归指标
metrics = [
tf.keras.metrics.MeanSquaredError(),
tf.keras.metrics.MeanAbsoluteError(),
tf.keras.metrics.RootMeanSquaredError()
]
# 常用分类指标
metrics = [
tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
tf.keras.metrics.AUC()
]
# 常用回归指标
metrics = [
tf.keras.metrics.MeanSquaredError(),
tf.keras.metrics.MeanAbsoluteError(),
tf.keras.metrics.RootMeanSquaredError()
]
2.2 评估流程
1. 编译模型时指定指标
实例
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', tf.keras.metrics.AUC()]
)
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', tf.keras.metrics.AUC()]
)
2. 使用 evaluate 方法评估
实例
test_loss, test_acc, test_auc = model.evaluate(
test_images, test_labels, verbose=2
)
test_images, test_labels, verbose=2
)
3. 自定义评估函数
实例
import tensorflow as tf
@tf.function
def custom_metric(y_true, y_pred):
threshold = 0.5
y_pred = tf.cast(y_pred > threshold, tf.float32)
# 计算准确率,而不仅仅是正例比例
correct_predictions = tf.cast(tf.equal(y_true, y_pred), tf.float32)
return tf.reduce_mean(correct_predictions)
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=[custom_metric, 'accuracy'] # 可以同时保留标准准确率指标作为参考
)
@tf.function
def custom_metric(y_true, y_pred):
threshold = 0.5
y_pred = tf.cast(y_pred > threshold, tf.float32)
# 计算准确率,而不仅仅是正例比例
correct_predictions = tf.cast(tf.equal(y_true, y_pred), tf.float32)
return tf.reduce_mean(correct_predictions)
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=[custom_metric, 'accuracy'] # 可以同时保留标准准确率指标作为参考
)
三、模型监控与可视化
1. TensorBoard 集成
TensorBoard 是 TensorFlow 的可视化工具,可以实时监控训练过程。
实例
# 设置回调函数
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir='./logs',
histogram_freq=1,
write_graph=True,
write_images=True
)
# 训练模型时添加回调
model.fit(
train_data,
epochs=10,
validation_data=val_data,
callbacks=[tensorboard_callback]
)
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir='./logs',
histogram_freq=1,
write_graph=True,
write_images=True
)
# 训练模型时添加回调
model.fit(
train_data,
epochs=10,
validation_data=val_data,
callbacks=[tensorboard_callback]
)
启动 TensorBoard:
tensorboard --logdir=./logs
2. 监控的关键指标
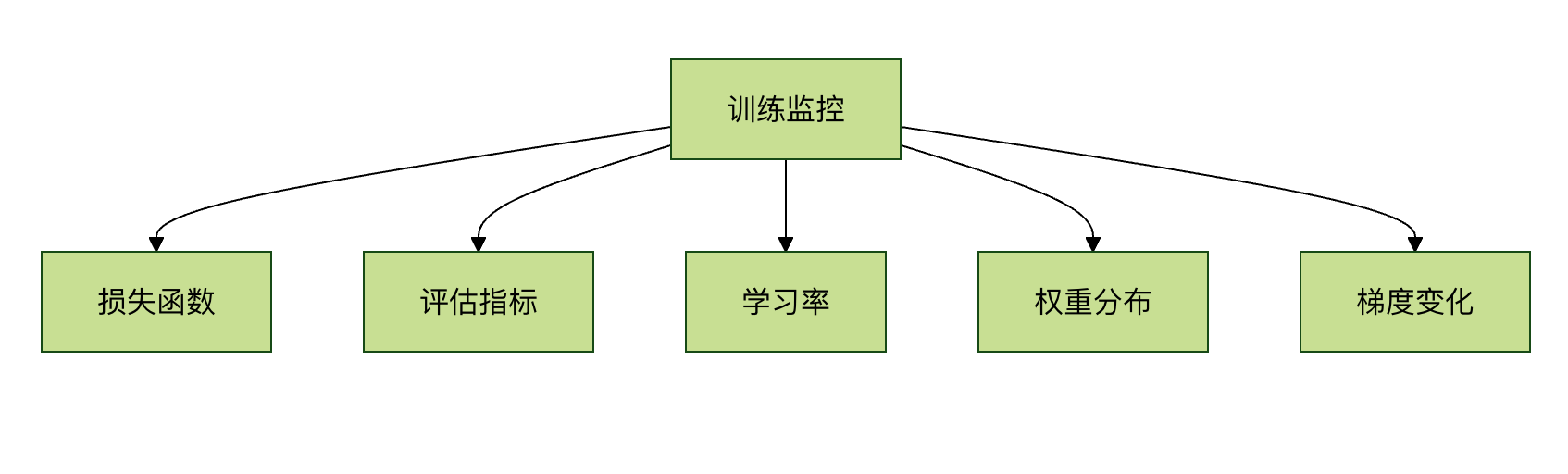
四、高级评估技术
4.1 交叉验证
实例
from sklearn.model_selection import KFold
import numpy as np
# 准备数据
X = np.array(...)
y = np.array(...)
# 5折交叉验证
kfold = KFold(n_splits=5, shuffle=True)
fold_no = 1
for train, test in kfold.split(X, y):
# 创建模型
model = create_model()
# 训练模型
model.fit(X[train], y[train], epochs=10)
# 评估模型
scores = model.evaluate(X[test], y[test])
print(f'Fold {fold_no} - {model.metrics_names[0]}: {scores[0]}')
fold_no += 1
import numpy as np
# 准备数据
X = np.array(...)
y = np.array(...)
# 5折交叉验证
kfold = KFold(n_splits=5, shuffle=True)
fold_no = 1
for train, test in kfold.split(X, y):
# 创建模型
model = create_model()
# 训练模型
model.fit(X[train], y[train], epochs=10)
# 评估模型
scores = model.evaluate(X[test], y[test])
print(f'Fold {fold_no} - {model.metrics_names[0]}: {scores[0]}')
fold_no += 1
4.2 混淆矩阵分析
实例
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 获取预测结果
y_pred = model.predict(test_images)
y_pred_classes = np.argmax(y_pred, axis=1)
# 生成混淆矩阵
conf_mat = confusion_matrix(test_labels, y_pred_classes)
# 可视化
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
import seaborn as sns
import matplotlib.pyplot as plt
# 获取预测结果
y_pred = model.predict(test_images)
y_pred_classes = np.argmax(y_pred, axis=1)
# 生成混淆矩阵
conf_mat = confusion_matrix(test_labels, y_pred_classes)
# 可视化
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
五、模型部署后监控
5.1 生产环境监控要点
- 数据漂移检测:监控输入数据分布变化
- 概念漂移检测:监控特征与目标关系变化
- 性能衰减检测:定期评估模型性能
- 异常输入检测:识别异常输入样本
5.2 监控系统架构
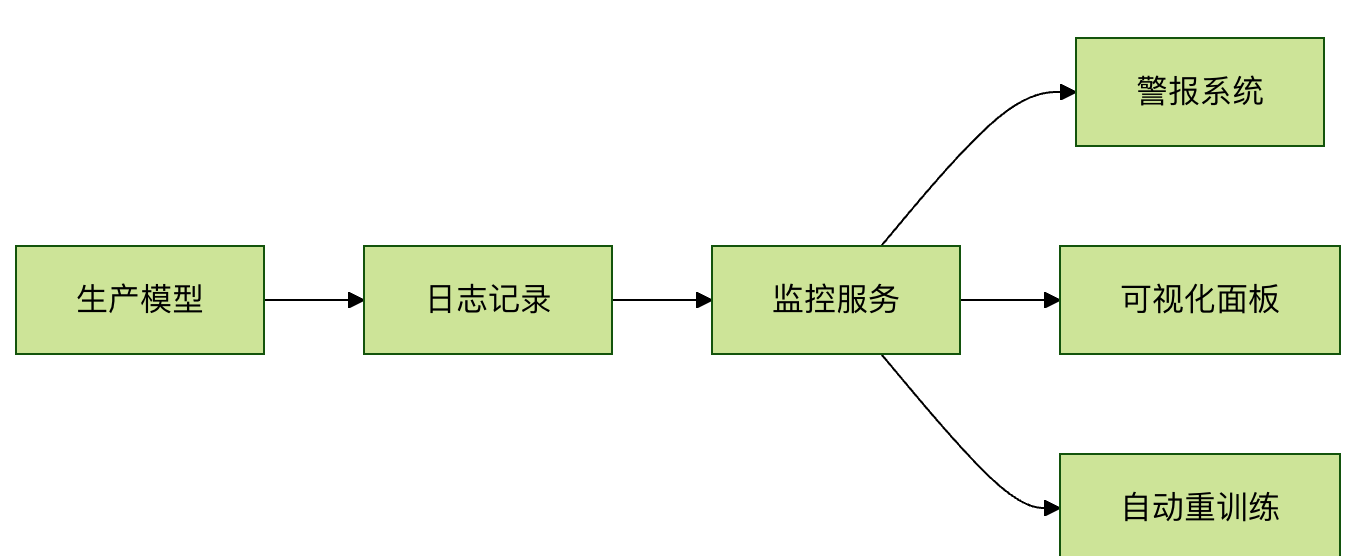
六、实践练习
6.1 练习任务
- 在 MNIST 数据集上训练一个简单的 CNN 模型
- 实现以下评估功能:
- 训练过程中的准确率和损失监控
- 测试集上的混淆矩阵分析
- 使用 TensorBoard 可视化训练过程
- 尝试实现自定义评估指标
6.2 参考代码框架
实例
import tensorflow as tf
from tensorflow.keras import layers
# 1. 数据准备
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# 2. 模型构建
model = tf.keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(10, activation='softmax')
])
# 3. 编译模型(添加你选择的指标)
model.compile(...)
# 4. 训练模型(添加TensorBoard回调)
history = model.fit(...)
# 5. 评估模型
test_loss, test_acc = model.evaluate(...)
# 6. 混淆矩阵分析
# 你的代码...
from tensorflow.keras import layers
# 1. 数据准备
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# 2. 模型构建
model = tf.keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(10, activation='softmax')
])
# 3. 编译模型(添加你选择的指标)
model.compile(...)
# 4. 训练模型(添加TensorBoard回调)
history = model.fit(...)
# 5. 评估模型
test_loss, test_acc = model.evaluate(...)
# 6. 混淆矩阵分析
# 你的代码...

点我分享笔记