文本分类
文本分类(Text Classification)是自然语言处理(NLP)中最基础也是最重要的任务之一。它的目标是将给定的文本文档自动归类到一个或多个预定义的类别中。
基本概念
文本分类就像图书馆的图书管理员,需要根据书籍的内容将它们分门别类地放到正确的书架上。在计算机领域,我们需要教会机器如何理解文本内容并做出正确的分类决策。
应用场景
文本分类在现代社会中有着广泛的应用:
- 情感分析:判断评论是正面还是负面
- 垃圾邮件过滤:区分正常邮件和垃圾邮件
- 新闻分类:将新闻归类到体育、财经、科技等板块
- 意图识别:理解用户查询的真实意图
- 医疗诊断:根据症状描述分类疾病类型
文本分类的基本流程
一个完整的文本分类系统通常包含以下几个步骤:
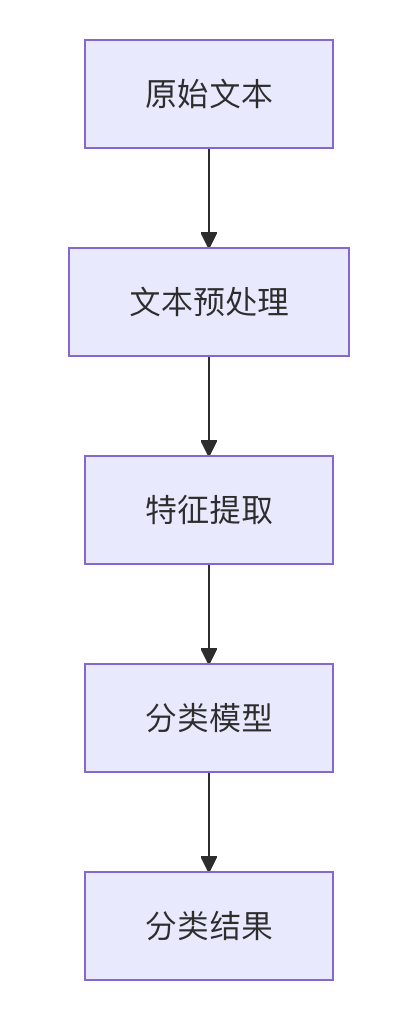
1. 文本预处理
文本预处理是将原始文本转换为适合机器学习模型处理的形式:
实例
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
def preprocess_text(text):
# 转换为小写
text = text.lower()
# 移除特殊字符和数字
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 分词
words = text.split()
# 移除停用词
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
# 词干提取
stemmer = PorterStemmer()
words = [stemmer.stem(word) for word in words]
return ' '.join(words)
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
def preprocess_text(text):
# 转换为小写
text = text.lower()
# 移除特殊字符和数字
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 分词
words = text.split()
# 移除停用词
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
# 词干提取
stemmer = PorterStemmer()
words = [stemmer.stem(word) for word in words]
return ' '.join(words)
2. 特征提取
将文本转换为数值特征表示,常见方法包括:
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 词袋模型(BoW) | 统计词频 | 简单直观 | 忽略词序和语义 |
| TF-IDF | 考虑词的重要性 | 比BoW更精确 | 仍然忽略上下文 |
| Word2Vec | 词向量表示 | 捕捉语义关系 | 无法处理多义词 |
| BERT | 上下文嵌入 | 最先进的表示 | 计算资源要求高 |
3. 分类模型选择
根据任务需求和数据特点选择合适的分类算法:
传统机器学习方法:
- 朴素贝叶斯
- 支持向量机(SVM)
- 逻辑回归
- 随机森林
深度学习方法:
- 卷积神经网络(CNN)
- 循环神经网络(RNN/LSTM)
- Transformer模型(BERT等)
实践示例:新闻分类
让我们通过一个实际的例子来演示如何使用Python实现文本分类。我们将使用20 Newsgroups数据集,这是一个经典的新闻分类数据集。
1. 数据准备
实例
from sklearn.datasets import fetch_20newsgroups
# 选择4个类别作为示例
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
# 加载训练集和测试集
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
print(f"训练集样本数: {len(newsgroups_train.data)}")
print(f"测试集样本数: {len(newsgroups_test.data)}")
# 选择4个类别作为示例
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
# 加载训练集和测试集
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
print(f"训练集样本数: {len(newsgroups_train.data)}")
print(f"测试集样本数: {len(newsgroups_test.data)}")
2. 特征提取(TF-IDF)
实例
from sklearn.feature_extraction.text import TfidfVectorizer
# 创建TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=5000)
# 转换训练集和测试集
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
y_train = newsgroups_train.target
y_test = newsgroups_test.target
# 创建TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=5000)
# 转换训练集和测试集
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
y_train = newsgroups_train.target
y_test = newsgroups_test.target
3. 模型训练(逻辑回归)
实例
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 创建并训练模型
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
print(f"准确率: {accuracy_score(y_test, y_pred):.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=newsgroups_test.target_names))
from sklearn.metrics import accuracy_score, classification_report
# 创建并训练模型
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
print(f"准确率: {accuracy_score(y_test, y_pred):.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=newsgroups_test.target_names))
4. 结果分析
典型的输出结果可能如下:
准确率: 0.91
分类报告:
precision recall f1-score support
alt.atheism 0.90 0.87 0.89 319
soc.religion.christian 0.93 0.95 0.94 389
comp.graphics 0.89 0.90 0.90 396
sci.med 0.92 0.91 0.92 398
accuracy 0.91 1502
macro avg 0.91 0.91 0.91 1502
weighted avg 0.91 0.91 0.91 1502
进阶技巧与挑战
处理类别不平衡
当某些类别的样本数量远多于其他类别时,可以尝试:
- 重采样(过采样少数类或欠采样多数类)
- 使用类别权重
- 尝试不同的评估指标(如F1-score而不是准确率)
提高模型性能的方法
特征工程:
- 尝试不同的n-gram范围
- 加入词性特征
- 使用更高级的词嵌入
模型优化:
- 超参数调优
- 模型集成
- 尝试深度学习模型
数据增强:
- 回译(Back Translation)
- 同义词替换
- 生成对抗网络(GAN)
常见挑战
- 多标签分类:一个文档可能属于多个类别
- 领域适应:模型在新领域的表现下降
- 小样本学习:标注数据有限的情况
- 解释性:理解模型为何做出特定分类决策
总结与学习路径
文本分类是NLP的基础任务,掌握它对于理解更复杂的NLP应用至关重要。建议的学习路径:
- 从传统机器学习方法(如TF-IDF + SVM)开始
- 理解词嵌入(Word2Vec, GloVe)的概念和应用
- 学习深度学习模型(CNN, LSTM)在文本分类中的应用
- 探索预训练语言模型(BERT, GPT)的迁移学习
通过不断实践和尝试不同的方法,你将能够构建出强大且实用的文本分类系统。

点我分享笔记