Python 迭代器模式
想象一下,你有一个装满各种颜色糖果的罐子。你想要一颗一颗地品尝这些糖果,但又不想一次性把所有糖果都倒出来。这时候,你会伸手到罐子里,一次取出一颗糖果——这个过程就是迭代。
在编程中,迭代器模式 是一种设计模式,它提供了一种方法,让我们能够顺序访问一个集合对象中的各个元素,而又不需要暴露该对象的内部表示。
核心概念
迭代器模式包含两个主要组成部分:
- 迭代器 (Iterator):负责定义访问和遍历元素的接口
- 可迭代对象 (Iterable):提供创建迭代器的方法
在 Python 中,迭代器模式已经被深度集成到语言的核心特性中,让我们的编程变得更加优雅和直观。
为什么需要迭代器?
传统方式的局限性
让我们先看一个没有使用迭代器的例子:
实例
# 一个简单的书籍集合类
class BookCollection:
def __init__(self):
self.books = ["Python入门", "算法导论", "设计模式", "数据结构"]
def get_books(self):
return self.books
# 使用这个集合
collection = BookCollection()
books = collection.get_books()
# 遍历书籍 - 暴露了内部实现细节
for i in range(len(books)):
print(books[i])
class BookCollection:
def __init__(self):
self.books = ["Python入门", "算法导论", "设计模式", "数据结构"]
def get_books(self):
return self.books
# 使用这个集合
collection = BookCollection()
books = collection.get_books()
# 遍历书籍 - 暴露了内部实现细节
for i in range(len(books)):
print(books[i])
问题分析:
- 客户端代码需要知道集合的内部结构(列表)
- 如果集合的内部实现改变(比如从列表改为字典),所有客户端代码都需要修改
- 遍历逻辑与集合实现紧密耦合
迭代器的优势
实例
# 使用迭代器的方式
for book in collection:
print(book)
for book in collection:
print(book)
迭代器带来的好处:
- 封装性:隐藏集合的内部实现
- 统一接口:不同的集合类型可以使用相同的遍历方式
- 灵活性:可以轻松更换集合的实现方式
- 支持多种遍历:可以同时进行多个遍历操作
Python 中的迭代器协议
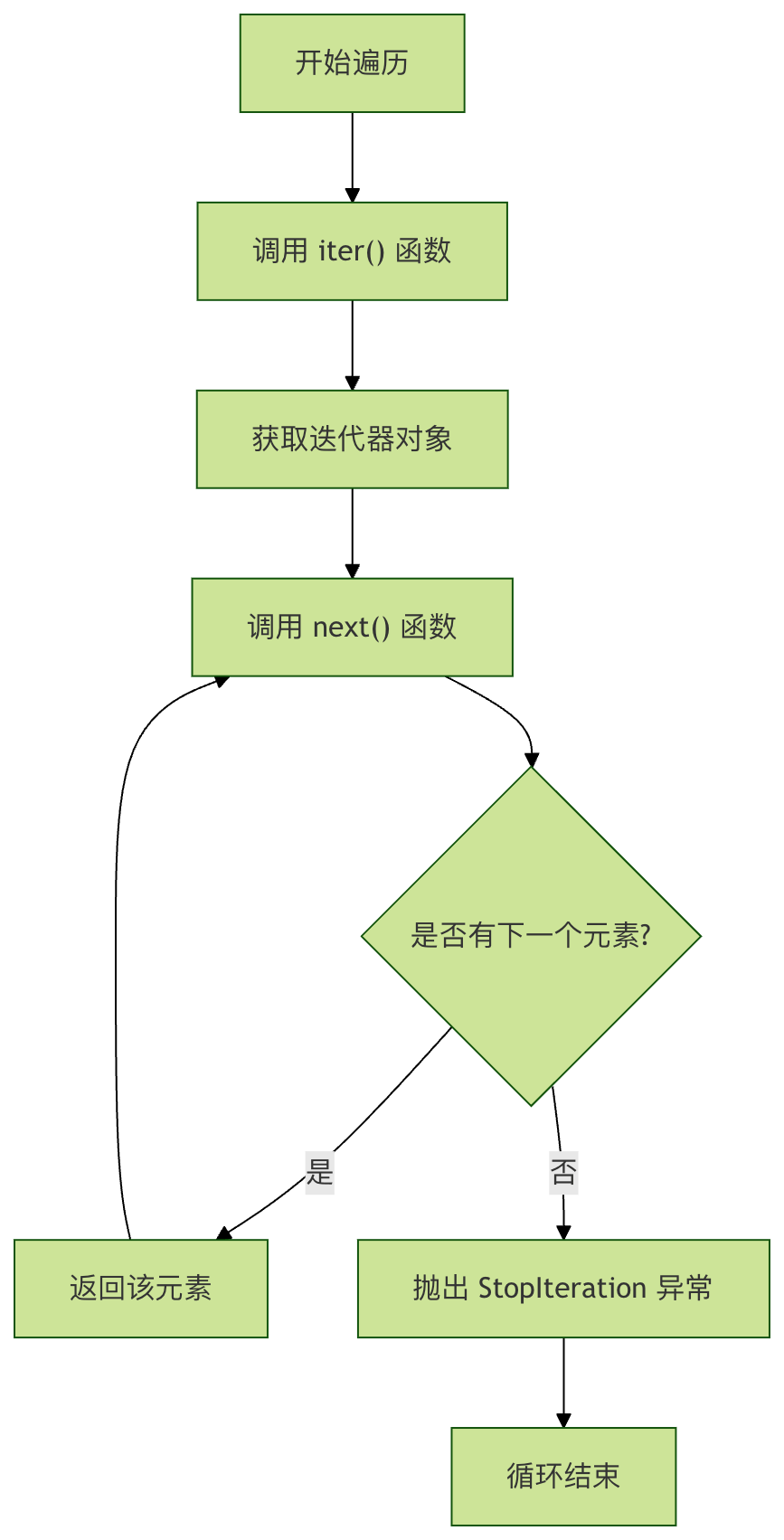
Python 通过两个特殊方法实现了迭代器协议:
__iter__() 方法
- 返回一个迭代器对象
- 可迭代对象必须实现这个方法
__next__() 方法
- 返回序列中的下一个元素
- 当没有更多元素时,抛出
StopIteration异常
让我们通过一个流程图来理解迭代器的工作机制:
创建自定义迭代器
方法一:使用类实现迭代器
让我们创建一个自定义的书籍迭代器:
实例
class BookIterator:
"""书籍迭代器类"""
def __init__(self, books):
self.books = books
self.index = 0
def __iter__(self):
"""返回迭代器自身"""
return self
def __next__(self):
"""返回下一本书,如果没有更多书则抛出StopIteration"""
if self.index < len(self.books):
book = self.books[self.index]
self.index += 1
return book
else:
raise StopIteration
class BookCollection:
"""可迭代的书籍集合类"""
def __init__(self):
self.books = ["Python入门", "算法导论", "设计模式", "数据结构"]
def __iter__(self):
"""返回一个迭代器实例"""
return BookIterator(self.books)
# 使用自定义迭代器
collection = BookCollection()
for book in collection:
print(f"正在阅读: {book}")
"""书籍迭代器类"""
def __init__(self, books):
self.books = books
self.index = 0
def __iter__(self):
"""返回迭代器自身"""
return self
def __next__(self):
"""返回下一本书,如果没有更多书则抛出StopIteration"""
if self.index < len(self.books):
book = self.books[self.index]
self.index += 1
return book
else:
raise StopIteration
class BookCollection:
"""可迭代的书籍集合类"""
def __init__(self):
self.books = ["Python入门", "算法导论", "设计模式", "数据结构"]
def __iter__(self):
"""返回一个迭代器实例"""
return BookIterator(self.books)
# 使用自定义迭代器
collection = BookCollection()
for book in collection:
print(f"正在阅读: {book}")
输出结果:
正在阅读: Python入门 正在阅读: 算法导论 正在阅读: 设计模式 正在阅读: 数据结构
方法二:使用生成器函数
Python 提供了更简洁的方式——生成器函数:
实例
class BookCollection:
def __init__(self):
self.books = ["Python入门", "算法导论", "设计模式", "数据结构"]
def __iter__(self):
"""使用生成器函数创建迭代器"""
for book in self.books:
yield book
# 使用方式完全相同
collection = BookCollection()
for book in collection:
print(f"阅读: {book}")
def __init__(self):
self.books = ["Python入门", "算法导论", "设计模式", "数据结构"]
def __iter__(self):
"""使用生成器函数创建迭代器"""
for book in self.books:
yield book
# 使用方式完全相同
collection = BookCollection()
for book in collection:
print(f"阅读: {book}")
生成器的优势:
- 代码更简洁
- 自动处理状态保存
- 性能更好
迭代器的实际应用场景
场景一:分页数据读取
实例
class PaginatedData:
"""模拟分页数据迭代器"""
def __init__(self, total_items, page_size=3):
self.total_items = total_items
self.page_size = page_size
self.current_page = 0
def __iter__(self):
return self
def __next__(self):
start = self.current_page * self.page_size
end = start + self.page_size
if start >= self.total_items:
raise StopIteration
# 模拟从数据库读取一页数据
page_data = list(range(start, min(end, self.total_items)))
self.current_page += 1
return page_data
# 使用分页迭代器
paginator = PaginatedData(10, 3) # 总共10条数据,每页3条
for page_num, page_data in enumerate(paginator, 1):
print(f"第{page_num}页数据: {page_data}")
"""模拟分页数据迭代器"""
def __init__(self, total_items, page_size=3):
self.total_items = total_items
self.page_size = page_size
self.current_page = 0
def __iter__(self):
return self
def __next__(self):
start = self.current_page * self.page_size
end = start + self.page_size
if start >= self.total_items:
raise StopIteration
# 模拟从数据库读取一页数据
page_data = list(range(start, min(end, self.total_items)))
self.current_page += 1
return page_data
# 使用分页迭代器
paginator = PaginatedData(10, 3) # 总共10条数据,每页3条
for page_num, page_data in enumerate(paginator, 1):
print(f"第{page_num}页数据: {page_data}")
输出结果:
第1页数据: [0, 1, 2] 第2页数据: [3, 4, 5] 第3页数据: [6, 7, 8] 第4页数据: [9]
场景二:无限序列生成
实例
class FibonacciIterator:
"""斐波那契数列迭代器"""
def __init__(self, max_count=10):
self.max_count = max_count
self.count = 0
self.a, self.b = 0, 1
def __iter__(self):
return self
def __next__(self):
if self.count >= self.max_count:
raise StopIteration
result = self.a
self.a, self.b = self.b, self.a + self.b
self.count += 1
return result
# 生成斐波那契数列
fib = FibonacciIterator(8)
print("斐波那契数列:", list(fib))
"""斐波那契数列迭代器"""
def __init__(self, max_count=10):
self.max_count = max_count
self.count = 0
self.a, self.b = 0, 1
def __iter__(self):
return self
def __next__(self):
if self.count >= self.max_count:
raise StopIteration
result = self.a
self.a, self.b = self.b, self.a + self.b
self.count += 1
return result
# 生成斐波那契数列
fib = FibonacciIterator(8)
print("斐波那契数列:", list(fib))
输出结果:
斐波那契数列: [0, 1, 1, 2, 3, 5, 8, 13]
内置迭代器工具
Python 提供了丰富的内置函数来操作迭代器:
iter() 和 next() 函数
实例
numbers = [1, 2, 3, 4, 5]
# 手动使用迭代器
iterator = iter(numbers)
print(next(iterator)) # 输出: 1
print(next(iterator)) # 输出: 2
print(next(iterator)) # 输出: 3
# 手动使用迭代器
iterator = iter(numbers)
print(next(iterator)) # 输出: 1
print(next(iterator)) # 输出: 2
print(next(iterator)) # 输出: 3
enumerate() 函数
实例
fruits = ['apple', 'banana', 'orange']
for index, fruit in enumerate(fruits):
print(f"索引 {index}: {fruit}")
for index, fruit in enumerate(fruits):
print(f"索引 {index}: {fruit}")
zip() 函数
实例
names = ['Alice', 'Bob', 'Charlie']
scores = [85, 92, 78]
for name, score in zip(names, scores):
print(f"{name} 得分: {score}")
scores = [85, 92, 78]
for name, score in zip(names, scores):
print(f"{name} 得分: {score}")
迭代器 vs 可迭代对象
理解这两个概念的区别很重要:
| 特性 | 可迭代对象 (Iterable) | 迭代器 (Iterator) |
|---|---|---|
| 定义 | 实现了 __iter__() 方法的对象 |
实现了 __iter__() 和 __next__() 方法的对象 |
| 用途 | 可以被迭代 | 实际执行迭代操作 |
| 状态 | 通常无状态 | 维护迭代状态(当前位置等) |
| 示例 | 列表、元组、字典、字符串 | iter() 返回的对象 |
关系图示
实例
graph TD
A[可迭代对象] -->|调用iter| B[迭代器]
B -->|重复调用next| C[逐个元素]
C --> D[直到StopIteration]
A[可迭代对象] -->|调用iter| B[迭代器]
B -->|重复调用next| C[逐个元素]
C --> D[直到StopIteration]
最佳实践和常见错误
最佳实践
- 使用生成器简化代码
实例
# 推荐:使用生成器
def countdown(n):
while n > 0:
yield n
n -= 1
# 不推荐:手动实现迭代器类
def countdown(n):
while n > 0:
yield n
n -= 1
# 不推荐:手动实现迭代器类
- 利用内置函数
实例
# 推荐
squares = (x*x for x in range(10)) # 生成器表达式
# 不推荐
class SquareIterator:
# ... 冗长的实现
squares = (x*x for x in range(10)) # 生成器表达式
# 不推荐
class SquareIterator:
# ... 冗长的实现
常见错误
错误 1:混淆迭代器和可迭代对象
实例
numbers = [1, 2, 3]
# 错误:列表本身不是迭代器
try:
next(numbers) # TypeError: 'list' object is not an iterator
except TypeError as e:
print(f"错误: {e}")
# 正确:先获取迭代器
iterator = iter(numbers)
print(next(iterator)) # 输出: 1
# 错误:列表本身不是迭代器
try:
next(numbers) # TypeError: 'list' object is not an iterator
except TypeError as e:
print(f"错误: {e}")
# 正确:先获取迭代器
iterator = iter(numbers)
print(next(iterator)) # 输出: 1
错误 2:迭代器耗尽后继续使用
实例
numbers = [1, 2, 3]
iterator = iter(numbers)
print(list(iterator)) # 输出: [1, 2, 3]
print(list(iterator)) # 输出: [] - 迭代器已耗尽!
iterator = iter(numbers)
print(list(iterator)) # 输出: [1, 2, 3]
print(list(iterator)) # 输出: [] - 迭代器已耗尽!
实践练习
练习 1:创建自定义迭代器
创建一个 Countdown 类,实现从指定数字倒数到 1 的迭代器:
实例
class Countdown:
def __init__(self, start):
self.start = start
def __iter__(self):
# 你的代码在这里
current = self.start
while current > 0:
yield current
current -= 1
# 测试你的实现
for num in Countdown(5):
print(num) # 应该输出: 5, 4, 3, 2, 1
def __init__(self, start):
self.start = start
def __iter__(self):
# 你的代码在这里
current = self.start
while current > 0:
yield current
current -= 1
# 测试你的实现
for num in Countdown(5):
print(num) # 应该输出: 5, 4, 3, 2, 1
练习 2:文件行迭代器
创建一个迭代器,能够逐行读取文件并在每行前添加行号:
实例
class NumberedLines:
def __init__(self, filename):
self.filename = filename
def __iter__(self):
with open(self.filename, 'r', encoding='utf-8') as file:
for line_num, line in enumerate(file, 1):
yield f"{line_num}: {line.rstrip()}"
def __init__(self, filename):
self.filename = filename
def __iter__(self):
with open(self.filename, 'r', encoding='utf-8') as file:
for line_num, line in enumerate(file, 1):
yield f"{line_num}: {line.rstrip()}"
总结
迭代器模式是 Python 编程中极其重要的概念,它让我们能够:
- 统一访问:用相同的方式遍历不同的数据结构
- 封装实现:隐藏集合的内部结构
- 惰性计算:只在需要时生成数据,节省内存
- 组合使用:与生成器、推导式等特性完美配合
记住这个简单的原则:任何实现了 __iter__() 方法的对象都是可迭代的,任何实现了 __next__() 方法的对象都是迭代器。

点我分享笔记