TensorFlow 实例 - 回归问题
什么是回归问题
回归问题是机器学习中的一类重要问题,其目标是预测连续值输出。与分类问题(预测离散类别)不同,回归问题预测的是实数范围内的数值。
常见回归问题示例
- 房价预测:根据房屋面积、位置等特征预测价格
- 股票预测:根据历史数据预测未来股价
- 温度预测:根据气象数据预测未来温度
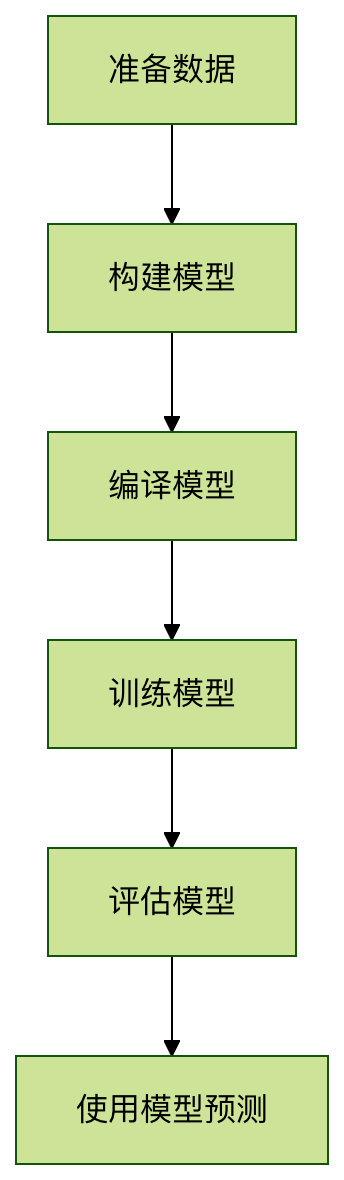
TensorFlow 解决回归问题的基本流程
实战:波士顿房价预测
1. 准备数据
我们将使用经典的波士顿房价数据集,它包含506个样本,每个样本有13个特征:
实例
from tensorflow.keras.datasets import boston_housing
# 加载数据
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
# 数据标准化(重要步骤)
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
# 加载数据
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
# 数据标准化(重要步骤)
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
2. 构建模型
实例
from tensorflow.keras import models
from tensorflow.keras import layers
def build_model():
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)),
layers.Dense(64, activation='relu'),
layers.Dense(1) # 输出层不需要激活函数
])
return model
from tensorflow.keras import layers
def build_model():
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)),
layers.Dense(64, activation='relu'),
layers.Dense(1) # 输出层不需要激活函数
])
return model
模型结构说明
- 输入层:对应13个特征
- 两个隐藏层:每层64个神经元,使用ReLU激活函数
- 输出层:1个神经元(预测房价),不使用激活函数
3. 编译模型
实例
model = build_model()
model.compile(optimizer='rmsprop',
loss='mse', # 均方误差
metrics=['mae']) # 平均绝对误差
model.compile(optimizer='rmsprop',
loss='mse', # 均方误差
metrics=['mae']) # 平均绝对误差
关键参数说明
- optimizer: 优化器,控制学习过程
rmsprop: 适合大多数问题的默认选择
- loss: 损失函数,回归问题常用
mse(Mean Squared Error): 均方误差
- metrics: 评估指标
mae(Mean Absolute Error): 平均绝对误差
4. 训练模型
实例
history = model.fit(train_data, train_targets,
epochs=100,
batch_size=16,
validation_split=0.2)
epochs=100,
batch_size=16,
validation_split=0.2)
参数解释
epochs: 训练轮数batch_size: 每批数据量validation_split: 验证集比例
5. 评估模型
实例
# 在测试集上评估
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
print(f"测试集MAE: {test_mae_score}")
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
print(f"测试集MAE: {test_mae_score}")
评估指标解读
- MAE (平均绝对误差): 预测值与真实值差距的平均值
- 例如MAE=2.5表示预测平均偏差2.5万美元
- MSE (均方误差): 对较大误差给予更大惩罚
6. 使用模型预测
实例
# 对新数据进行预测
sample = test_data[0] # 取测试集第一个样本
prediction = model.predict(sample.reshape(1, -1))
print(f"预测价格: {prediction[0][0]}, 实际价格: {test_targets[0]}")
sample = test_data[0] # 取测试集第一个样本
prediction = model.predict(sample.reshape(1, -1))
print(f"预测价格: {prediction[0][0]}, 实际价格: {test_targets[0]}")
模型优化技巧
1. 调整网络结构
实例
# 更深的网络可能表现更好
def build_deeper_model():
model = models.Sequential([
layers.Dense(128, activation='relu', input_shape=(train_data.shape[1],)),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(1)
])
return model
def build_deeper_model():
model = models.Sequential([
layers.Dense(128, activation='relu', input_shape=(train_data.shape[1],)),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(1)
])
return model
2. 使用K折交叉验证
实例
from sklearn.model_selection import KFold
k = 4
kf = KFold(n_splits=k)
for train_index, val_index in kf.split(train_data):
# 划分训练集和验证集
partial_train_data = train_data[train_index]
partial_train_targets = train_targets[train_index]
val_data = train_data[val_index]
val_targets = train_targets[val_index]
# 训练和评估模型
model = build_model()
model.fit(partial_train_data, partial_train_targets,
epochs=100, batch_size=16, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
print(f"验证MAE: {val_mae}")
k = 4
kf = KFold(n_splits=k)
for train_index, val_index in kf.split(train_data):
# 划分训练集和验证集
partial_train_data = train_data[train_index]
partial_train_targets = train_targets[train_index]
val_data = train_data[val_index]
val_targets = train_targets[val_index]
# 训练和评估模型
model = build_model()
model.fit(partial_train_data, partial_train_targets,
epochs=100, batch_size=16, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
print(f"验证MAE: {val_mae}")
3. 添加正则化防止过拟合
实例
from tensorflow.keras import regularizers
model = models.Sequential([
layers.Dense(64, activation='relu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(train_data.shape[1],)),
layers.Dense(64, activation='relu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(1)
])
model = models.Sequential([
layers.Dense(64, activation='relu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(train_data.shape[1],)),
layers.Dense(64, activation='relu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(1)
])
常见问题与解决方案
问题1: 模型表现不稳定
- 原因: 数据量小或初始化随机性
- 解决: 增加数据量或使用K折交叉验证
问题2: 训练误差低但测试误差高
- 原因: 过拟合
- 解决: 添加Dropout层或L2正则化
问题3: 预测值偏离实际值很多
- 原因: 数据未标准化或网络结构不合理
- 解决: 检查数据预处理步骤,调整网络深度和宽度

点我分享笔记