TensorFlow 模型转换与优化
在机器学习项目开发中,模型转换与优化是部署前的重要步骤。
TensorFlow 提供了多种工具和技术来帮助开发者将训练好的模型转换为适合不同部署环境的格式,并对其进行优化以提高性能。
为什么需要模型转换与优化
- 部署需求:训练好的模型需要适配不同平台(移动端、嵌入式设备、服务器等)
- 性能提升:优化可以减少模型大小、降低延迟、提高推理速度
- 资源限制:移动设备和边缘计算设备通常有严格的内存和计算资源限制
- 跨平台兼容:确保模型能在不同硬件架构和操作系统上运行
主要转换与优化技术
| 技术类型 | 主要工具 | 适用场景 |
|---|---|---|
| 模型格式转换 | tf.saved_model, TFLiteConverter |
跨平台部署 |
| 量化 | TFLiteConverter |
减小模型大小,提高推理速度 |
| 剪枝 | tfmot |
减少参数数量 |
| 硬件加速 | TensorRT, Core ML | 特定硬件优化 |
模型格式转换
SavedModel 格式
SavedModel 是 TensorFlow 的标准模型保存格式,包含完整的模型架构、权重和计算图。
实例
import tensorflow as tf
# 保存为 SavedModel
model.save('my_model', save_format='tf')
# 加载 SavedModel
loaded_model = tf.keras.models.load_model('my_model')
# 保存为 SavedModel
model.save('my_model', save_format='tf')
# 加载 SavedModel
loaded_model = tf.keras.models.load_model('my_model')
关键特点:
- 包含模型的计算图和变量
- 支持签名定义(输入/输出规范)
- 跨平台兼容(支持 TensorFlow Serving)
TensorFlow Lite 转换
TensorFlow Lite 是针对移动和嵌入式设备的轻量级解决方案。
实例
# 转换模型为 TFLite 格式
converter = tf.lite.TFLiteConverter.from_saved_model('my_model')
tflite_model = converter.convert()
# 保存转换后的模型
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
converter = tf.lite.TFLiteConverter.from_saved_model('my_model')
tflite_model = converter.convert()
# 保存转换后的模型
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
转换选项:
optimizations:设置优化级别(默认、大小优化、延迟优化)target_spec:指定目标设备特性representative_dataset:用于量化校准的数据集
模型优化技术
量化(Quantization)
量化通过降低数值精度来减小模型大小和提高推理速度。
实例
# 动态范围量化(最简单的量化方式)
converter = tf.lite.TFLiteConverter.from_saved_model('my_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
converter = tf.lite.TFLiteConverter.from_saved_model('my_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
量化类型对比:
| 量化类型 | 权重精度 | 激活精度 | 大小减少 | 精度损失 |
|---|---|---|---|---|
| 无量化 | FP32 | FP32 | 0% | 无 |
| 动态范围 | INT8 | FP32 | ~75% | 小 |
| 全整型 | INT8 | INT8 | ~75% | 中等 |
| FP16 | FP16 | FP16 | ~50% | 很小 |
剪枝(Pruning)
剪枝通过移除不重要的神经元连接来减少模型参数。
实例
import tensorflow_model_optimization as tfmot
# 定义剪枝参数
prune_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(
initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=0,
end_step=1000
)
}
# 应用剪枝
model = tf.keras.Sequential([...]) # 你的模型
model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(model, **prune_params)
# 训练剪枝模型
model_for_pruning.compile(...)
model_for_pruning.fit(...)
# 去除剪枝包装
model_for_export = tfmot.sparsity.keras.strip_pruning(model_for_pruning)
# 定义剪枝参数
prune_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(
initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=0,
end_step=1000
)
}
# 应用剪枝
model = tf.keras.Sequential([...]) # 你的模型
model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(model, **prune_params)
# 训练剪枝模型
model_for_pruning.compile(...)
model_for_pruning.fit(...)
# 去除剪枝包装
model_for_export = tfmot.sparsity.keras.strip_pruning(model_for_pruning)
硬件特定优化
TensorRT 优化(NVIDIA GPU)
实例
# 使用 TF-TRT 转换器
from tensorflow.python.compiler.tensorrt import trt_convert as trt
converter = trt.TrtGraphConverterV2(
input_saved_model_dir='my_model',
precision_mode=trt.TrtPrecisionMode.FP16
)
converter.convert()
converter.save('trt_optimized_model')
from tensorflow.python.compiler.tensorrt import trt_convert as trt
converter = trt.TrtGraphConverterV2(
input_saved_model_dir='my_model',
precision_mode=trt.TrtPrecisionMode.FP16
)
converter.convert()
converter.save('trt_optimized_model')
Core ML 转换(Apple 设备)
实例
import coremltools as ct
# 从 SavedModel 转换
mlmodel = ct.convert('my_model')
# 保存 Core ML 模型
mlmodel.save('model.mlmodel')
# 从 SavedModel 转换
mlmodel = ct.convert('my_model')
# 保存 Core ML 模型
mlmodel.save('model.mlmodel')
最佳实践与常见问题
转换优化流程
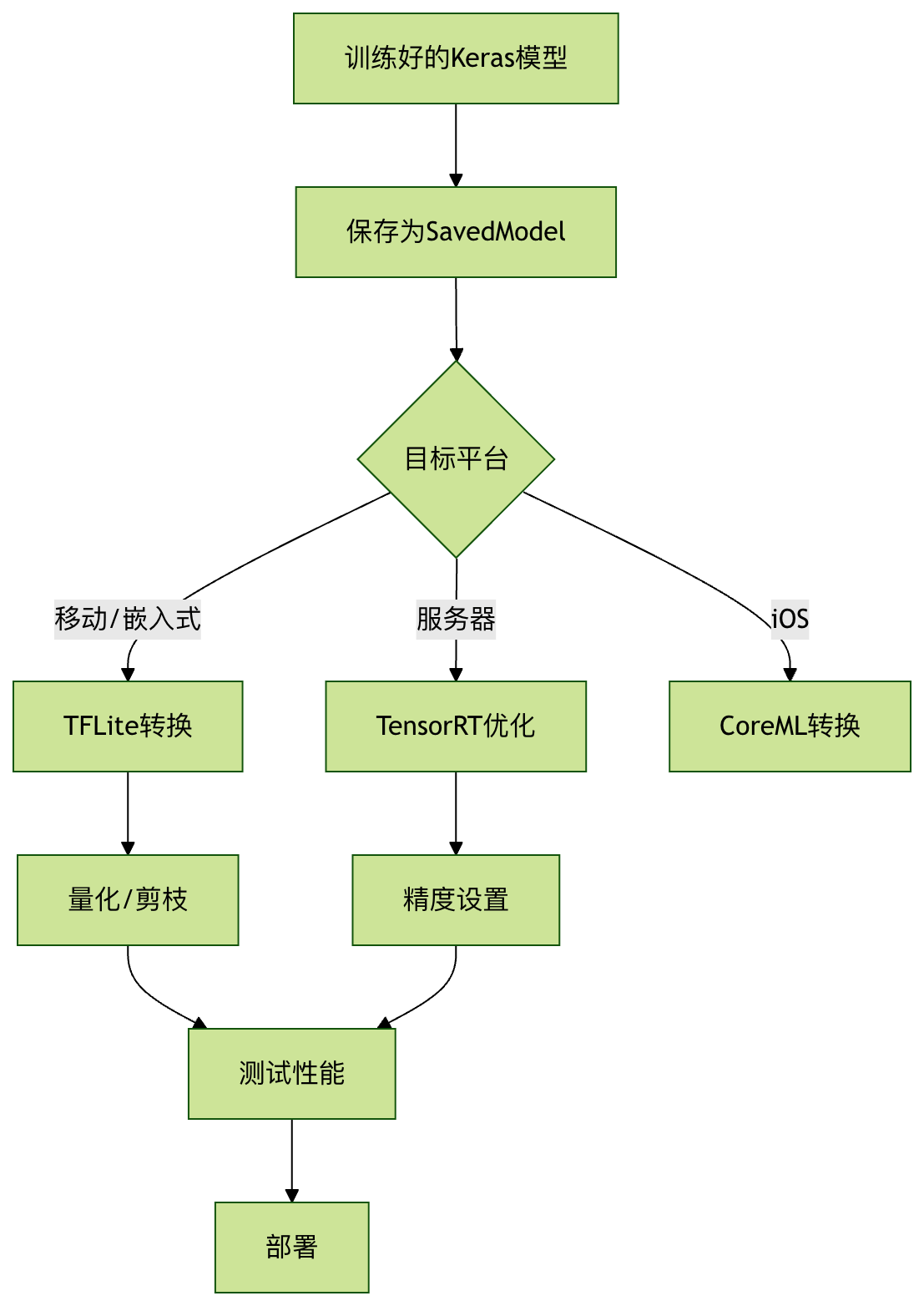
常见问题解决
精度下降过多
- 尝试混合量化(部分层保持FP32)
- 使用量化感知训练(QAT)
转换后模型无法运行
- 检查操作兼容性(某些操作可能不被目标平台支持)
- 更新TensorFlow和转换器版本
性能提升不明显
- 确保正确设置了优化选项
- 考虑模型架构本身是否适合目标硬件

点我分享笔记