PyTorch torch.optim 优化器模块
优化器是深度学习中的核心组件,负责根据损失函数的梯度调整模型参数,使模型能够逐步逼近最优解。在PyTorch中,torch.optim模块提供了多种优化算法的实现。
为什么需要优化器
- 自动化参数更新:手动计算和更新每个参数非常繁琐
- 加速收敛:使用优化算法比普通梯度下降更快找到最优解
- 避免局部最优:某些优化器具有跳出局部最优的能力
常见优化器类型
| 优化器名称 | 主要特点 | 适用场景 |
|---|---|---|
| SGD | 简单基础 | 基础教学、简单模型 |
| Adam | 自适应学习率 | 大多数深度学习任务 |
| RMSprop | 适应学习率 | RNN网络 |
| Adagrad | 参数独立学习率 | 稀疏数据 |
优化器核心API
基本使用流程
实例
import torch.optim as optim
# 1. 定义模型
model = MyModel()
# 2. 创建优化器实例
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 训练循环
for epoch in range(epochs):
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
# 参数更新
optimizer.step() # 更新参数
# 1. 定义模型
model = MyModel()
# 2. 创建优化器实例
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 训练循环
for epoch in range(epochs):
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
# 参数更新
optimizer.step() # 更新参数
关键方法说明
- zero_grad():清空参数的梯度缓存
- step():执行单次参数更新
- state_dict():获取优化器状态(可用于保存和加载)
- load_state_dict():加载优化器状态
常用优化器详解
SGD (随机梯度下降)
实例
optim.SGD(params, lr=0.01, momentum=0, dampening=0,
weight_decay=0, nesterov=False)
weight_decay=0, nesterov=False)
核心参数:
lr(float):学习率(默认0.01)momentum(float):动量因子(默认0)weight_decay(float):L2正则化系数(默认0)
特点:
- 最简单的优化算法
- 可以添加动量项加速收敛
- 适合作为基准比较
Adam (自适应矩估计)
实例
optim.Adam(params, lr=0.001, betas=(0.9, 0.999),
eps=1e-08, weight_decay=0, amsgrad=False)
eps=1e-08, weight_decay=0, amsgrad=False)
核心参数:
betas(Tuple[float, float]):用于计算梯度和梯度平方的移动平均系数eps(float):数值稳定项(默认1e-8)amsgrad(bool):是否使用AMSGrad变体(默认False)
特点:
- 自适应学习率
- 结合了动量概念
- 大多数情况下的默认选择
优化器高级技巧
学习率调度
实例
from torch.optim.lr_scheduler import StepLR
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step() # 更新学习率
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step() # 更新学习率
参数分组优化
实例
optim.SGD([
{'params': model.base.parameters()}, # 基础层
{'params': model.classifier.parameters(), 'lr': 1e-3} # 分类层
], lr=1e-2)
{'params': model.base.parameters()}, # 基础层
{'params': model.classifier.parameters(), 'lr': 1e-3} # 分类层
], lr=1e-2)
梯度裁剪
实例
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
优化器选择指南
选择依据
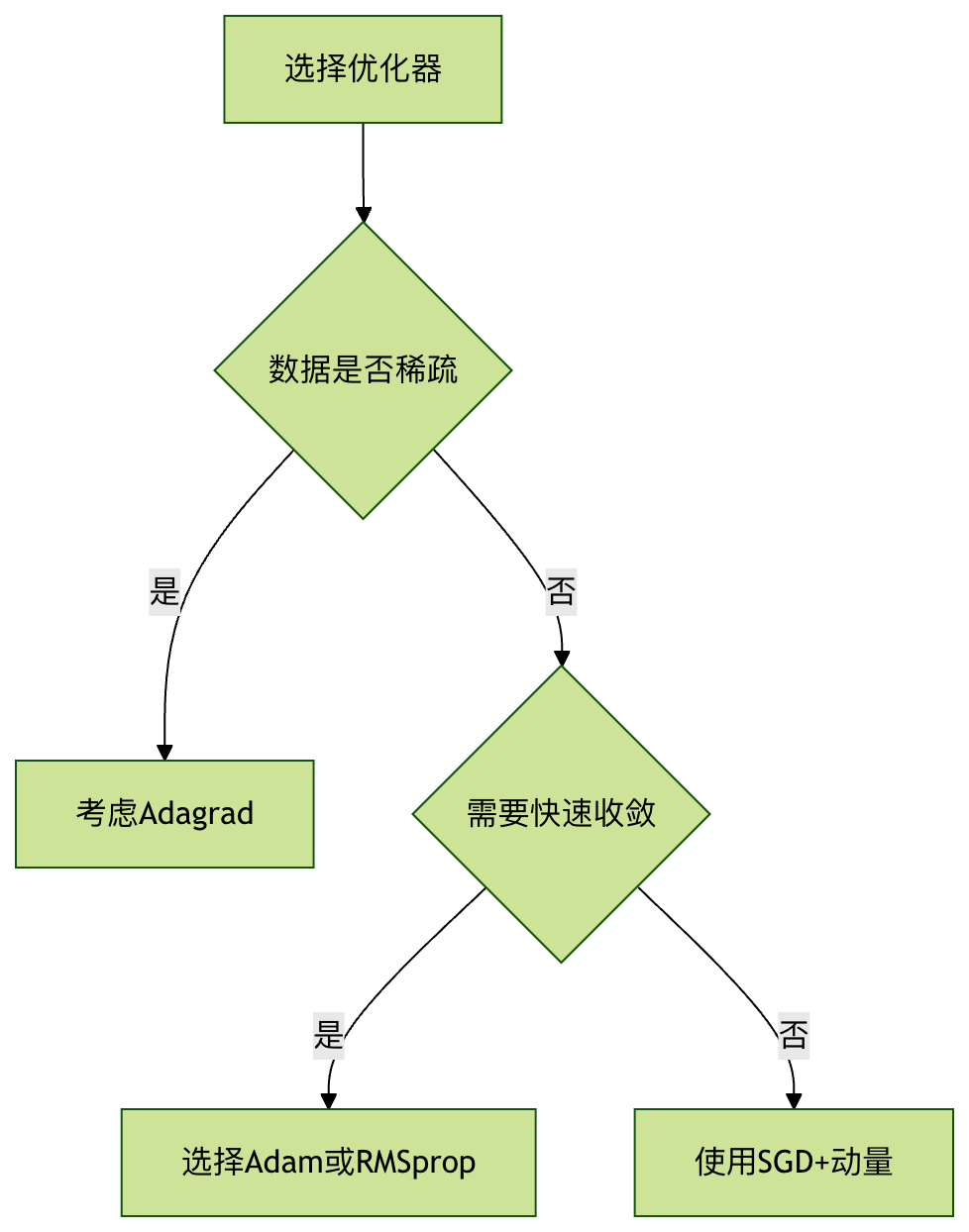
性能对比
| 优化器 | 收敛速度 | 内存占用 | 超参数敏感度 |
|---|---|---|---|
| SGD | 慢 | 低 | 高 |
| Adam | 快 | 中 | 低 |
| RMSprop | 中 | 中 | 中 |

点我分享笔记