PyTorch 模型保存和加载
在深度学习项目中,模型保存和加载是至关重要的环节,主要原因包括:
- 训练中断恢复:当训练过程意外中断时,可以从保存点继续训练
- 模型部署:将训练好的模型部署到生产环境
- 模型共享:方便团队成员之间共享模型成果
- 迁移学习:保存预训练模型用于其他任务
- 性能评估:保存不同训练阶段的模型进行比较
基本保存和加载方法
保存整个模型
这是最简单的方法,保存模型的架构和参数:
实例
import torch
import torchvision.models as models
# 创建并训练一个模型
model = models.resnet18(pretrained=True)
# ... 训练代码 ...
# 保存整个模型
torch.save(model, 'model.pth')
# 加载整个模型
loaded_model = torch.load('model.pth')
import torchvision.models as models
# 创建并训练一个模型
model = models.resnet18(pretrained=True)
# ... 训练代码 ...
# 保存整个模型
torch.save(model, 'model.pth')
# 加载整个模型
loaded_model = torch.load('model.pth')
优点:
- 代码简单直观
- 保存了完整的模型结构
缺点:
- 文件体积较大
- 对模型类的定义有依赖
仅保存模型参数(推荐方式)
更推荐的方式是只保存模型的状态字典(state_dict):
实例
# 保存模型参数
torch.save(model.state_dict(), 'model_weights.pth')
# 加载模型参数
model = models.resnet18() # 必须先创建相同架构的模型
model.load_state_dict(torch.load('model_weights.pth'))
model.eval() # 设置为评估模式
torch.save(model.state_dict(), 'model_weights.pth')
# 加载模型参数
model = models.resnet18() # 必须先创建相同架构的模型
model.load_state_dict(torch.load('model_weights.pth'))
model.eval() # 设置为评估模式
优点:
- 文件更小
- 更灵活,可以加载到不同架构中
- 兼容性更好
保存和加载训练状态
在实际项目中,我们通常还需要保存优化器状态、epoch等信息:
实例
# 保存检查点
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
# 可以添加其他需要保存的信息
}
torch.save(checkpoint, 'checkpoint.pth')
# 加载检查点
checkpoint = torch.load('checkpoint.pth')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval() # 或者 model.train() 取决于你的需求
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
# 可以添加其他需要保存的信息
}
torch.save(checkpoint, 'checkpoint.pth')
# 加载检查点
checkpoint = torch.load('checkpoint.pth')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval() # 或者 model.train() 取决于你的需求
跨设备加载模型
CPU/GPU兼容性处理
实例
# 保存时指定map_location
torch.save(model.state_dict(), 'model_weights.pth')
# 加载到CPU(当模型是在GPU上训练时)
device = torch.device('cpu')
model.load_state_dict(torch.load('model_weights.pth', map_location=device))
# 加载到GPU
device = torch.device('cuda')
model.load_state_dict(torch.load('model_weights.pth', map_location=device))
model.to(device)
torch.save(model.state_dict(), 'model_weights.pth')
# 加载到CPU(当模型是在GPU上训练时)
device = torch.device('cpu')
model.load_state_dict(torch.load('model_weights.pth', map_location=device))
# 加载到GPU
device = torch.device('cuda')
model.load_state_dict(torch.load('model_weights.pth', map_location=device))
model.to(device)
多GPU训练模型加载
实例
# 保存多GPU模型
torch.save(model.module.state_dict(), 'multigpu_model.pth')
# 加载到单GPU
model = ModelClass()
model.load_state_dict(torch.load('multigpu_model.pth'))
torch.save(model.module.state_dict(), 'multigpu_model.pth')
# 加载到单GPU
model = ModelClass()
model.load_state_dict(torch.load('multigpu_model.pth'))
模型转换与兼容性
PyTorch版本兼容性
实例
# 保存时指定_use_new_zipfile_serialization=True以获得更好的兼容性
torch.save(model.state_dict(), 'model.pth', _use_new_zipfile_serialization=True)
torch.save(model.state_dict(), 'model.pth', _use_new_zipfile_serialization=True)
转换为TorchScript
实例
# 将模型转换为TorchScript格式
scripted_model = torch.jit.script(model)
torch.jit.save(scripted_model, 'model_scripted.pt')
# 加载TorchScript模型
loaded_script = torch.jit.load('model_scripted.pt')
scripted_model = torch.jit.script(model)
torch.jit.save(scripted_model, 'model_scripted.pt')
# 加载TorchScript模型
loaded_script = torch.jit.load('model_scripted.pt')
最佳实践与常见问题
最佳实践
- 命名规范:使用有意义的文件名,如
resnet18_epoch50.pth - 定期保存:每隔几个epoch保存一次检查点
- 验证加载:保存后立即测试加载功能
- 文档记录:记录模型架构和训练参数
- 版本控制:将模型文件纳入版本控制系统
常见问题解决方案
问题1:Missing key(s) in state_dict
解决:确保模型架构完全匹配,或使用strict=False参数:
model.load_state_dict(torch.load('model.pth'), strict=False)
问题2:CUDA out of memory
解决:加载时先放到CPU:
实例
model.load_state_dict(torch.load('model.pth', map_location='cpu'))
问题3:无法加载旧版本模型
解决:尝试在不同PyTorch版本中加载,或转换模型格式
实际应用示例
图像分类模型保存与加载流程
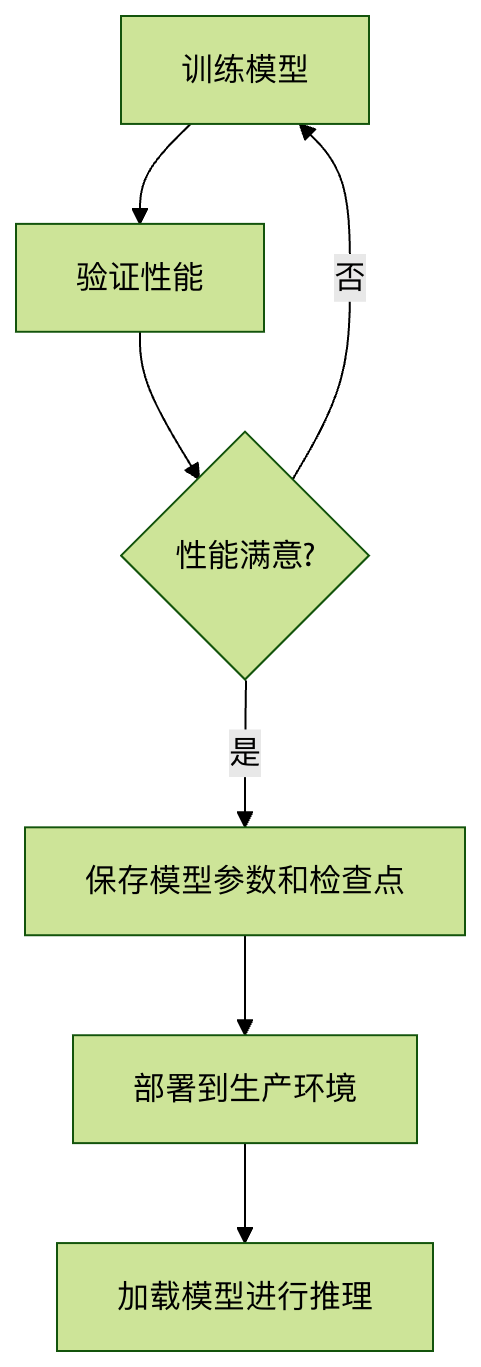
完整代码示例
实例
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
# 初始化
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
# 模拟训练过程
for epoch in range(5):
# 模拟训练步骤
inputs = torch.randn(32, 10)
labels = torch.randint(0, 2, (32,))
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每2个epoch保存一次检查点
if epoch % 2 == 0:
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss.item(),
}
torch.save(checkpoint, f'checkpoint_epoch{epoch}.pth')
print(f'Checkpoint saved at epoch {epoch}')
# 最终保存
torch.save(model.state_dict(), 'final_model.pth')
# 加载示例
loaded_model = SimpleModel()
loaded_model.load_state_dict(torch.load('final_model.pth'))
loaded_model.eval()
# 测试加载的模型
test_input = torch.randn(1, 10)
with torch.no_grad():
output = loaded_model(test_input)
print(f'Test output: {output}')
import torch.nn as nn
import torch.optim as optim
# 定义一个简单模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
# 初始化
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
# 模拟训练过程
for epoch in range(5):
# 模拟训练步骤
inputs = torch.randn(32, 10)
labels = torch.randint(0, 2, (32,))
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每2个epoch保存一次检查点
if epoch % 2 == 0:
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss.item(),
}
torch.save(checkpoint, f'checkpoint_epoch{epoch}.pth')
print(f'Checkpoint saved at epoch {epoch}')
# 最终保存
torch.save(model.state_dict(), 'final_model.pth')
# 加载示例
loaded_model = SimpleModel()
loaded_model.load_state_dict(torch.load('final_model.pth'))
loaded_model.eval()
# 测试加载的模型
test_input = torch.randn(1, 10)
with torch.no_grad():
output = loaded_model(test_input)
print(f'Test output: {output}')

点我分享笔记