
Python OpenAI
openai 是一个强大的 Python 库,用于与 OpenAI 的一系列模型和服务进行交互。
openai 封装了所有 RESTful API 调用,让开发者能轻松地在自己的 Python 应用中集成强大的 AI 能力,例如自然语言处理、图像生成和语音识别等。
主要功能:
- 文本生成:使用 GPT-4 或 GPT-5 等模型生成文章、代码、摘要、对话等。
- 图像生成:通过 DALL-E 模型根据文本描述创建图像。
- 嵌入(Embeddings):将文本转换成向量表示,常用于语义搜索、文本分类和聚类等任务。
- 语音转文本:使用 Whisper 模型将音频文件转录成文本。
- 微调(Fine-tuning):通过提供自己的数据集来训练一个更具针对性的模型。
- 助手(Assistants)API:构建能够理解上下文、调用工具并进行长期交互的复杂应用。
openai 开源地址:https://github.com/openai/openai-python

如何使用?
首先,你需要用 pip 安装 openai 库:
# 如果下述命令报错,请将pip替换为pip3 pip install openai
然后需要去 OpenAI 官网注册账号,并在 API 密钥页面生成一个 API Key。
实例
from openai import OpenAI
client = OpenAI(
# This is the default and can be omitted
api_key="你申请的 API key",
)
response = client.responses.create(
model="gpt-4o",
instructions="You are a coding assistant that talks like a pirate.",
input="How do I check if a Python object is an instance of a class?",
)
print(response.output_text)
我们国内目前访问 openai 还是有点麻烦,所以本章节采阿里云百炼的 AI 模型来调用演示,国内很多也支持 openai,比如 DeepSeek。
阿里云百炼的通义千问模型支持 OpenAI 兼容接口,您只需调整 API Key、BASE_URL 和模型名称,即可将原有 OpenAI 代码迁移至阿里云百炼服务使用。
我们需要开通阿里云百炼模型服务并获得 API-KEY。
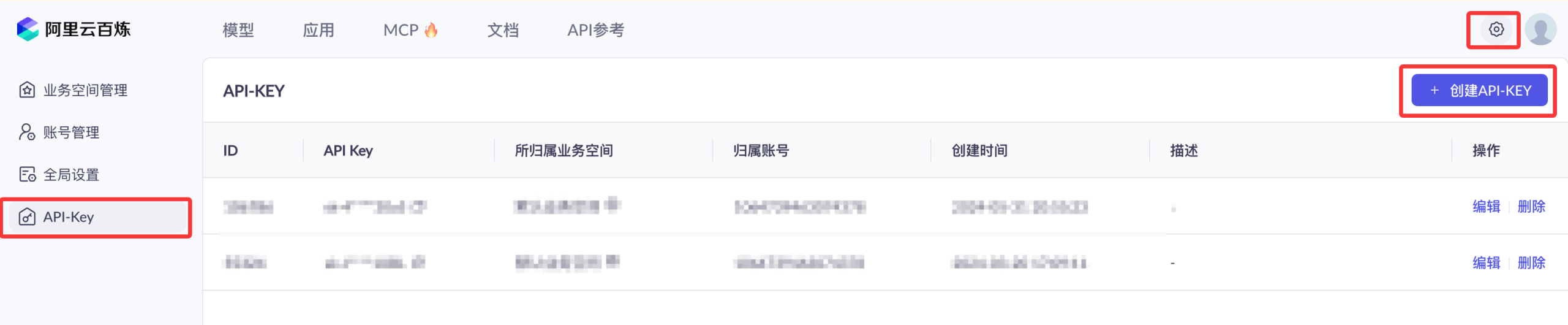
我们可以先使用阿里云主账号访问百炼模型服务平台:https://bailian.console.aliyun.com/,然后点击右上角登录,登录成功后点击右上角的齿轮⚙️图标,选择 API key,然后复制 API key,如果没有也可以创建 API key:

开通阿里云百炼不会产生费用,仅模型调用(超出免费额度后)、模型部署、模型调优会产生相应计费。
现在要使用 API,都需要按 token 来计费,还好都不贵,我们可以先购买个最便宜的包:阿里云百炼大模型服务平台。
使用方式
接下来我们使用 OpenAI SDK 访问百炼服务上的通义千问模型。
非流式调用示例
实例
import os
def get_response():
client = OpenAI(
api_key="sk-xxx", # 请用阿里云百炼 API Key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 填写DashScope SDK的base_url
)
completion = client.chat.completions.create(
model="qwen-plus", # 此处以qwen-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}]
)
# json 数据
#print(completion.model_dump_json())
print(completion.choices[0].message.content)
if __name__ == '__main__':
get_response()
运行代码可以获得以下结果:
我是通义千问,阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!
流式调用示例
实例
def get_response():
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
],
stream=True,
stream_options={"include_usage": True}
)
for chunk in completion:
# chunk 里可能没有 choices 或 delta
if hasattr(chunk, "choices") and len(chunk.choices) > 0:
choice = chunk.choices[0]
if hasattr(choice, "delta") and hasattr(choice.delta, "content"):
print(choice.delta.content, end='', flush=True)
if __name__ == '__main__':
get_response()
运行代码可以获得以下结果:
我是通义千问,阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!
参考手册
| 分类 | 方法 / 属性 | 方法 / 属性 | >功能说明示例代码 |
|---|---|---|---|
| 安装与导入 | pip install openai | 安装官方 Python SDK | import openai |
| 客户端初始化 | openai.OpenAI(api_key="API_KEY") | 创建客户端对象 | client = openai.OpenAI(api_key="sk-xxx") |
| 模型管理 | client.models.list() | 获取可用模型列表 | models = client.models.list() |
| 文本补全 | client.completions.create() | 根据提示生成文本 | client.completions.create(model="text-davinci-003", prompt="你好", max_tokens=50) |
| 聊天生成 | client.chat.completions.create() | 基于消息生成对话 | client.chat.completions.create(model="gpt-3.5-turbo", messages=[{'role':'user','content':'你好'}]) |
| 流式输出 | stream=True | 边生成边输出 | for chunk in client.chat.completions.create(…, stream=True): print(chunk.choices[0].delta.content, end='') |
| 上传文件 | client.files.upload() | 上传训练或微调文件 | client.files.upload(file=open("data.jsonl","rb"), purpose="fine-tune") |
| 查看文件 | client.files.list() | 获取文件列表 | client.files.list() |
| 微调模型 | client.fine_tunes.create() | 对模型进行微调 | client.fine_tunes.create(training_file="file-xxx", model="davinci") |
| 生成嵌入 | client.embeddings.create() | 获取文本向量 | client.embeddings.create(input="Hello world", model="text-embedding-3-small") |
| 音频转文本 | client.audio.transcriptions.create() | 将音频转为文字 | client.audio.transcriptions.create(file=open("audio.mp3","rb"), model="whisper-1") |
| 错误处理 | openai.error.OpenAIError | 捕获 SDK 错误 | try: … except openai.error.OpenAIError as e: print(e) |
| 配置超时 | client = OpenAI(api_key="xxx", timeout=30) | 设置请求超时 | client = OpenAI(api_key="sk-xxx", timeout=30) |
更多 API 参考:https://github.com/openai/openai-python/blob/main/api.md

点我分享笔记