Node.js 工作机制
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,它让开发者能够使用 JavaScript 编写服务器端代码。与传统的服务器端技术不同,Node.js 采用了事件驱动和非阻塞 I/O模型,这使得它特别适合处理高并发的网络应用。
核心特点
- 单线程:Node.js 使用单线程处理请求
- 事件循环:通过事件驱动机制处理并发
- 非阻塞 I/O:I/O 操作不会阻塞主线程
- 跨平台:可以在 Windows、Linux、macOS 等系统上运行
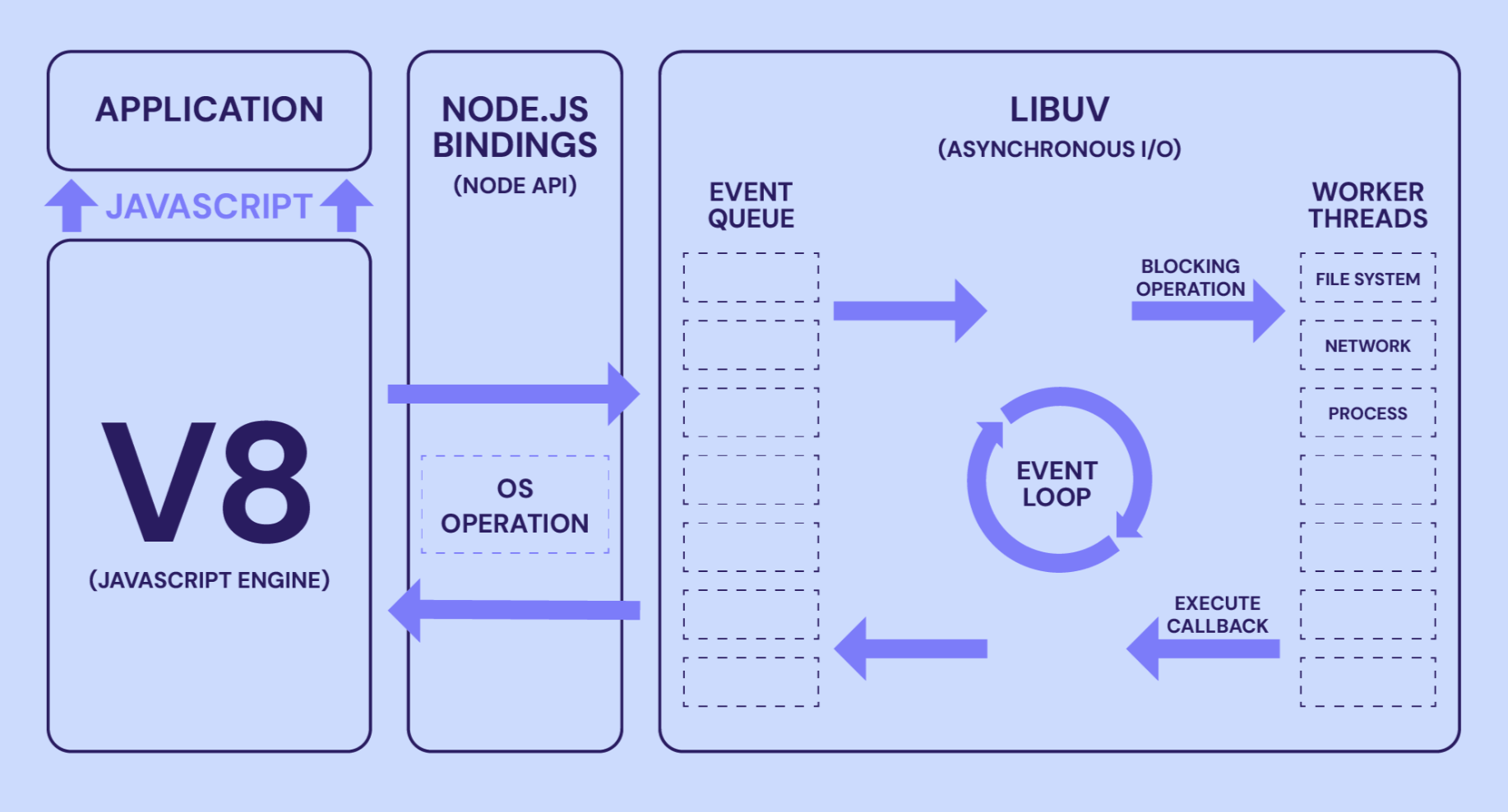
Node.js 通过 V8 引擎执行 JavaScript 代码,使用 Node.js API 与操作系统交互,并通过 Libuv 处理异步 I/O 操作。事件循环和工作线程确保了 Node.js 的高效和非阻塞特性。
-
V8 JavaScript Engine:这是 Node.js 的核心,负责执行 JavaScript 代码。V8 是 Chrome 浏览器的 JavaScript 引擎,它将 JavaScript 代码编译成机器码以提高执行效率。
-
Node.js Bindings (Node API):这一层提供了一组 API,允许 JavaScript 代码与操作系统进行交互。这些 API 包括文件系统、网络、进程等操作。
-
Libuv (Asynchronous I/O):Libuv 是一个跨平台的异步 I/O 库,它在 Node.js 下运行,用于处理文件系统、网络和进程等异步操作。Libuv 使用事件循环和工作线程来处理这些操作,而不会阻塞主线程。
-
Event Loop:这是 Node.js 的核心概念之一。事件循环不断检查事件队列,处理事件和执行回调函数。它确保了 Node.js 的非阻塞和事件驱动的特性。
-
Event Queue:事件队列用于存储即将处理的事件。当一个异步操作完成时,相关的回调函数会被放入事件队列中,等待事件循环处理。
-
Worker Threads:这些是用于处理阻塞操作的线程,如文件读写、网络请求等。它们允许 Node.js 在不阻塞主线程的情况下执行这些操作。
-
Blocking Operation:这些是可能阻塞线程的操作,如同步的文件读写。在 Node.js 中,这些操作通常被放在工作线程中执行,以避免阻塞事件循环。
-
Execute Callback:一旦一个异步操作完成,它的回调函数就会被执行。这是通过事件循环来管理的。
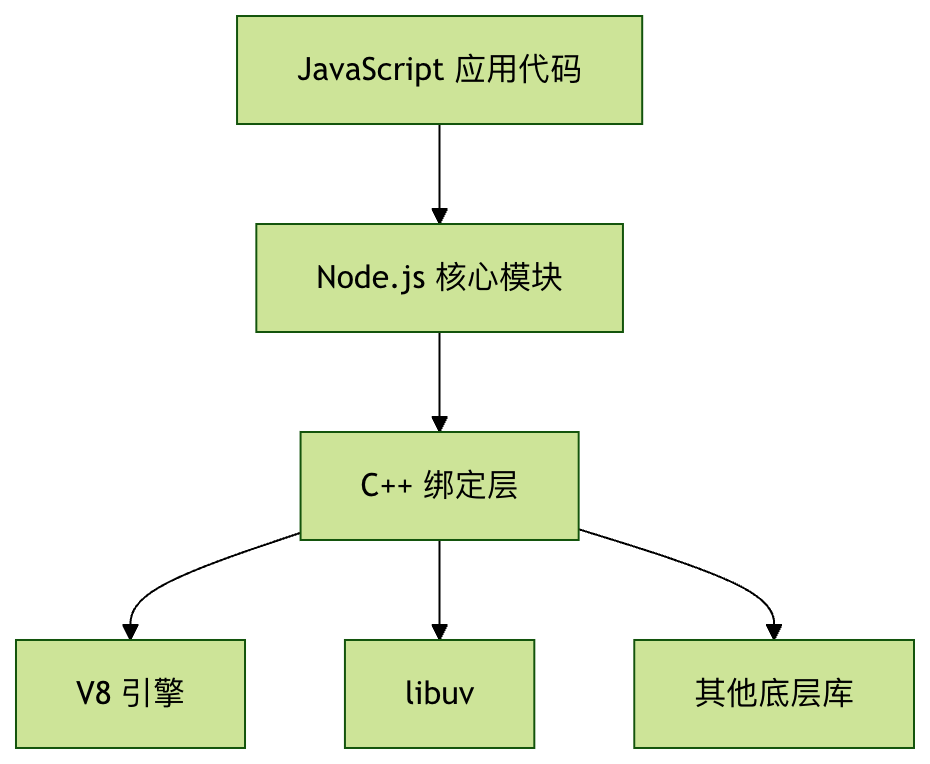
Node.js 的架构组成
Node.js 的架构可以分为以下几个主要层次:
1. JavaScript 层
这是开发者直接接触的层面,包括:
- 核心模块(如 fs、http、path 等)
- 第三方模块(通过 npm 安装)
- 用户自定义模块
2. C++ 绑定层
这一层将底层功能暴露给 JavaScript 层,包括:
- Node.js 核心 API 的 C++ 实现
- V8 引擎的接口封装
3. 底层依赖
- V8 引擎:Google 开发的 JavaScript 引擎
- libuv:跨平台的异步 I/O 库
- c-ares:异步 DNS 解析库
- OpenSSL:加密功能支持
- zlib:压缩功能支持
事件循环机制
Node.js 的核心工作机制是事件循环,它负责调度和执行所有异步操作。
事件循环的阶段
- timers:执行 setTimeout 和 setInterval 的回调
- pending callbacks:执行系统操作的回调(如 TCP 错误)
- idle, prepare:内部使用
- poll:检索新的 I/O 事件,执行相关回调
- check:执行 setImmediate 的回调
- close callbacks:执行关闭事件的回调(如 socket.on('close'))
实例
setTimeout(() => console.log('timeout'), 0);
setImmediate(() => console.log('immediate'));
// 输出顺序可能不同,取决于事件循环的启动时间
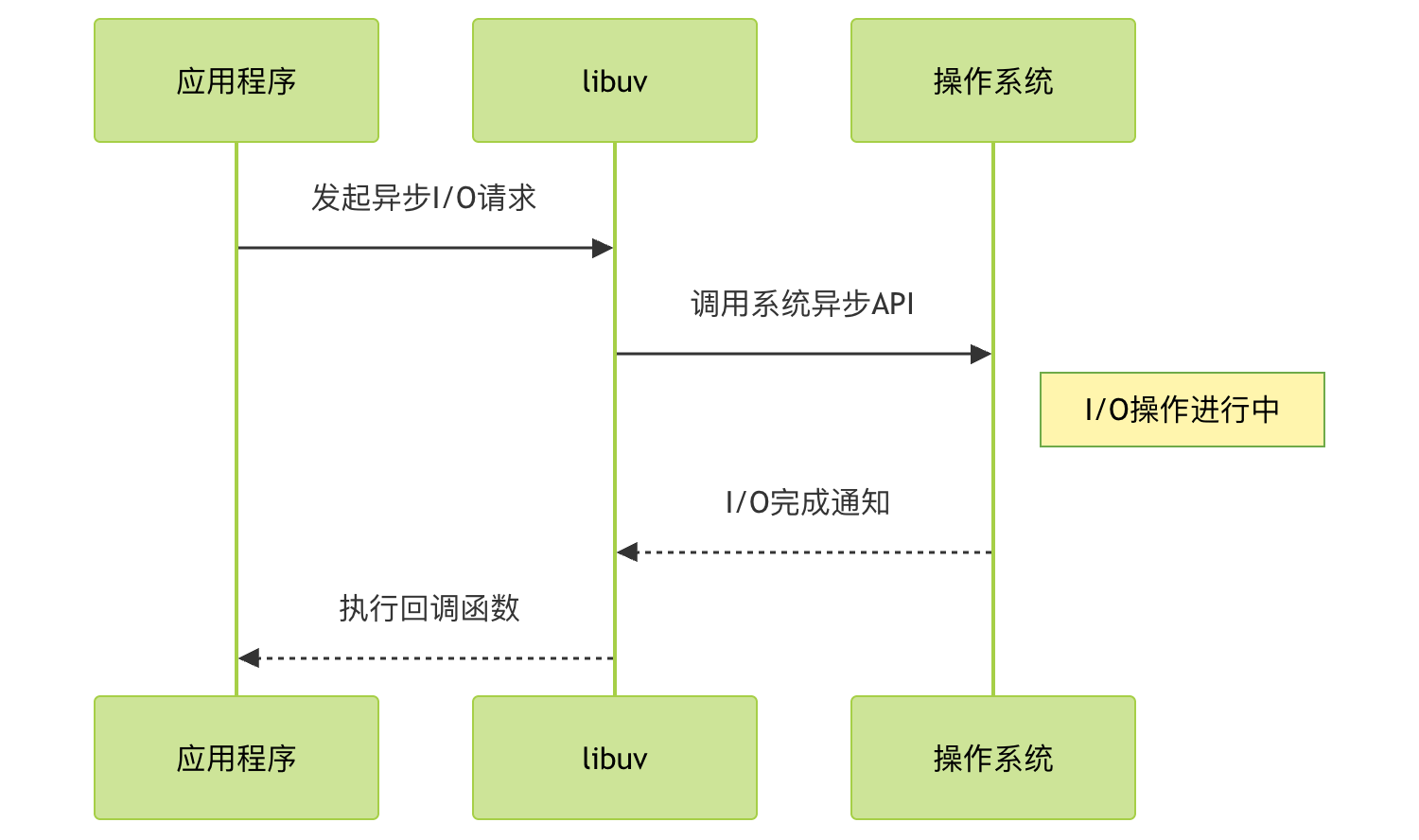
非阻塞 I/O 原理
Node.js 的 I/O 操作是非阻塞的,这是通过以下方式实现的:
工作流程
- 应用发起 I/O 请求(如读取文件)
- Node.js 将请求交给 libuv 处理
- libuv 使用系统提供的异步接口(如 Linux 的 epoll)
- 主线程继续执行其他任务
- I/O 完成后,回调函数被放入事件队列
- 事件循环在适当阶段执行回调
单线程与多进程
虽然 Node.js 是单线程的,但它可以通过以下方式利用多核 CPU:
1. 子进程 (child_process)
实例
const child = fork('child.js');
child.on('message', (msg) => {
console.log('来自子进程的消息:', msg);
});
child.send({ hello: 'world' });
2. 集群模式 (cluster)
实例
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// 主进程 fork 工作进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
// 工作进程创建HTTP服务器
http.createServer((req, res) => {
res.writeHead(200);
res.end('你好世界\n');
}).listen(8000);
}
3. Worker Threads (工作线程)
实例
const worker = new Worker(`
const { parentPort } = require('worker_threads');
parentPort.on('message', (msg) => {
console.log('收到消息:', msg);
parentPort.postMessage('消息已收到');
});
`, { eval: true });
worker.on('message', (msg) => {
console.log('来自工作线程的回复:', msg);
});
worker.postMessage('主线程消息');
性能优化建议
1、避免阻塞事件循环
- 将 CPU 密集型任务分流到工作线程或子进程
- 避免在主线程进行复杂计算
2、合理使用流处理
实例
fs.readFile('bigfile.txt', (err, data) => {
// 处理数据
});
// 好的做法:使用流
const stream = fs.createReadStream('bigfile.txt');
stream.on('data', (chunk) => {
// 处理数据块
});
3、连接池管理
- 数据库连接
- HTTP 客户端连接
4、内存管理
- 监控内存使用情况
- 避免内存泄漏
常见问题解答
Q: Node.js 真的是单线程吗?
A: JavaScript 执行是单线程的,但 Node.js 底层使用了多线程(如 libuv 的线程池处理某些 I/O 操作)。
Q: 如何处理 CPU 密集型任务?
A: 可以使用 Worker Threads 或将任务拆分为多个小任务,通过 setImmediate 分批处理。
Q: 为什么 Node.js 适合 I/O 密集型应用?
A: 因为它的非阻塞 I/O 模型可以在等待 I/O 时处理其他请求,而不需要为每个连接创建新线程。
总结
Node.js 的工作机制基于以下几个核心概念:
- 事件驱动的编程模型
- 非阻塞 I/O 操作
- 单线程但支持多进程/多线程扩展
- 高效的事件循环调度
理解这些机制对于编写高性能的 Node.js 应用至关重要。通过合理利用其异步特性,可以构建出能够处理高并发的网络应用。

点我分享笔记