由于 Hadoop 是为集群设计的软件,所以我们在学习它的使用时难免会遇到在多台计算机上配置 Hadoop 的情况,这对于学习者来说会制造诸多障碍,主要有两个:
- 昂贵的计算机集群。多计算机构成的集群环境需要昂贵的硬件.
- 难以部署和维护。在众多计算机上部署相同的软件环境是一个大量的工作,而且非常不灵活,难以在环境更改后重新部署。
为了解决这些问题,我们有一个非常成熟的方式 Docker。
Docker 是一个容器管理系统,它可以向虚拟机一样运行多个"虚拟机"(容器),并构成一个集群。因为虚拟机会完整的虚拟出一个计算机来,所以会消耗大量的硬件资源且效率低下,而 Docker 仅提供一个独立的、可复制的运行环境,实际上容器中所有进程依然在主机上的内核中被执行,因此它的效率几乎和主机上的进程一样(接近100%)。
本教程将会以 Docker 为底层环境来描述 Hadoop 的使用,如果你不会使用 Docker 并且不了解更好的方式,请学习 Docker 教程。
注:Windows 用户建议使用虚拟机方案安装 Docker。
Docker 部署
进入 Docker 命令行之后,拉取一个 Linux 镜像作为 Hadoop 运行的环境,这里推荐使用 CentOS 镜像(Debian 和其它镜像暂时会出现一些问题)。
docker pull centos:8
然后通过 docker images 命令可以查看到当前本地的镜像:
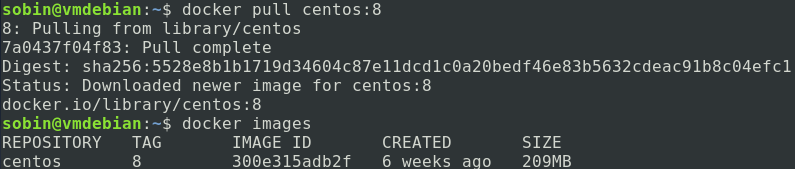
现在,我们创建一个容器:
docker run -d centos:8 /usr/sbin/init
通过 docker ps 可以查看运行中的容器:

我们可以令容器打印出 Hello World:

到这里说明 Docker 已经安装并部署成功。
创建容器
Hadoop 支持在单个设备上运行,主要有两种模式:单机模式和伪集群模式。
本章讲述 Hadoop 的安装与单机模式。
配置 Java 与 SSH 环境
现在创建一个容器,名为 java_ssh_proto,用于配置一个包含 Java 和 SSH 的环境:
docker run -d --name=java_ssh_proto --privileged centos:8 /usr/sbin/init
然后进入容器:
docker exec -it java_ssh_proto bash

配置镜像:
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/$contentdir|baseurl=https://mirrors.ustc.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-Stream-AppStream.repo \
/etc/yum.repos.d/CentOS-Stream-BaseOS.repo \
/etc/yum.repos.d/CentOS-Stream-Extras.repo \
/etc/yum.repos.d/CentOS-Stream-PowerTools.repo
安装 OpenJDK 8 和 SSH 服务:
yum install -y java-1.8.0-openjdk-devel openssh-clients openssh-server
然后启用 SSH 服务:
systemctl enable sshd && systemctl start sshd
如果是 ubuntu 系统,使用以下命令启动 SSH 服务:
systemctl enable ssh && systemctl start ssh
到这里为止,如果没有出现任何故障,一个包含 Java 运行环境和 SSH 环境的原型容器就被创建好了。这是一个非常关键的容器,建议大家在这里先在容器中用 exit 命令退出容器,然后运行以下下两条命令停止容器,并保存为一个名为 java_ssh 的镜像:
docker stop java_ssh_proto docker commit java_ssh_proto java_ssh
Hadoop 安装
下载 Hadoop
Hadoop 官网地址:http://hadoop.apache.org/
Hadoop 发行版本下载:https://hadoop.apache.org/releases.html
在目前的测试中,3.1.x 与 3.2.x 版本的兼容性较佳,本教程使用 3.1.4 版本作为案例。
Hadoop 3.1.4 镜像地址,下载好 tar.gz 压缩包文件备用。
创建 Hadoop 单机容器
现在以之前保存的 java_ssh 镜像创建容器 hadoop_single:
docker run -d --name=hadoop_single --privileged java_ssh /usr/sbin/init
将下载好的 hadoop 压缩包拷贝到容器中的 /root 目录下:
docker cp <你存放hadoop压缩包的路径> hadoop_single:/root/
进入容器:
docker exec -it hadoop_single bash
进入 /root 目录:
cd /root
这里应该存放着刚刚拷贝过来的 hadoop-x.x.x.tar.gz 文件,现在解压它:
tar -zxf hadoop-3.1.4.tar.gz
解压后将得到一个文件夹 hadoop-3.1.4,现在把它拷贝到一个常用的地方:
mv hadoop-3.1.4 /usr/local/hadoop
然后配置环境变量:
echo "export HADOOP_HOME=/usr/local/hadoop" >> /etc/bashrc echo "export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin" >> /etc/bashrc
然后退出 docker 容器并重新进入。
这时,echo $HADOOP_HOME 的结果应该是 /usr/local/hadoop
echo "export JAVA_HOME=/usr" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh echo "export HADOOP_HOME=/usr/local/hadoop" >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
这两步配置了 hadoop 内置的环境变量,然后执行以下命令判断是否成功:
hadoop version
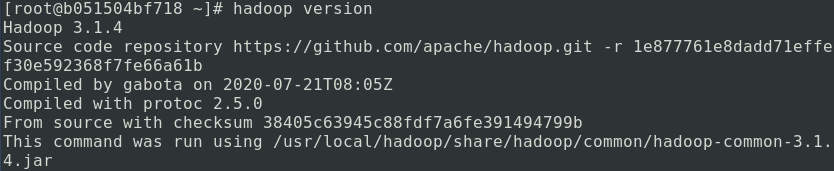
到这里,说明你的 Hadoop 单机版已经配置成功了。

点我分享笔记